Programmieren in C++
unter GNU/Linux-Systemen mit GCC
Inhaltsverzeichnis zu JMB's Seite über
die Programmierung in C++ mit GCC
unter GNU/Linux-Systemen
Basis zum Programmieren:
GNU/Linux und GCC
Betriebssystem GNU/Linux
als Programmierbasis
Es ist keine Frage, welches System sich
für das Programmieren am besten eignet:
🐧GNU/Linux.
![[Grafik mit TuX und GNU als Maskottchen von GNU/Linux]](images/tux_gnu_jmb_2026.gif)
Zunächst unterstützt kein anderes Beriebssystem
so viele Architekturen und ist in so vielen Einsatzbereichen
von ![[Wikipedia-de-Icon]](images/Wikipedia_logo_de.gif) Embedded Systemen
(wie Settop-Boxen),
über Raspberry Pi
(dieser Einplatinencomputer wird z.B. auch an Schulen
gerne verwendet), Smartphones/Tablets,
Desktops, Servern, Mainframes bis hin zu Supercomputern
zu Hause.
Embedded Systemen
(wie Settop-Boxen),
über Raspberry Pi
(dieser Einplatinencomputer wird z.B. auch an Schulen
gerne verwendet), Smartphones/Tablets,
Desktops, Servern, Mainframes bis hin zu Supercomputern
zu Hause.
Dies ist kein Wunder, da Unix und somit auch Linux
im Hinblick auf Portabilität (d.h. unproblematischem
Einsatz auf unterschiedlichen Prozessorarchitekturen durch Verwendung
der Programmiersprache C) entwickelt wurde und wird.
So wurde vor Kurzem ein Großteil
des Assemblercodes des Kernels Linux ersetzt,
da der Performancevorteil mittlerweile
durch bessere Compiler kaum ins Gewicht fällt,
aber beim Portieren und Warten von unterschiedlichen
Plattformen sehr viel Arbeit erfordert.
Die Wurzeln in freier Software wie GCC führen
zu einer Vielzahl an Programmiermöglichkeiten, Libraries,
Standards –
und das ohne einen Cent, alles im Quellcode
verfügbar, viele Anleitungen und Foren im Internet, ...
Erzeugen von Binaries
mit der GNU‑Compilersammlung GCC
Hierbei spielt die GNU Compiler Collection
(GCC)
eine sehr gewichtige Rolle.
Sie ist zentraler Bestandteil des GNU‑Systems,
startete als reiner C‑Compiler und kann mittlerweile
die Programmiersprachen:
C (gcc), C++ (g++), Objective‑C,
Objective‑C++, Fortran (gfortran, Verwendung), Ada,
D (gdc)𝔻 ,
Go (gccgo) und BRIG (HSAIL)
übersetzen [mit cpp
als C‑Präprozessor für C, C++ und
Objective C]
(vgl. von GCC unterstützte
Computersprachstandards) – zudem gibt es
einen GCC Cobol Anwärter gcobol
(noch Out‑Of‑Tree,
aber nach 16 Monaten [vgl. LWN‑Artikel,
15.03.2022, sowie offizielle Ankündigung,
14.03.2022] wurde er nun
als arbeitsfähiger Cobol‑85‑Kompilierer getestet;
vgl. LWN‑Artikel vom 10.02.2023;
{nicht zu verwechseln mit GnuCOBOL,
der Cobol nach C kompiliert und danach
gcc aufruft, um ausführbaren Code
zu erzeugen}; am 13.12.2024 wurden 8 Patche zur Überprüfung
zugeschickt, die das Erstellen und Benutzen
des COBOL Front‑Ends ermöglichen –
und nach Phoronix, 16.02.2025, besteht die Hoffnung,
dass gcobol noch in GCC 15.1
aufgenommen werden kann – was sich auch
bestätigte, siehe Phoronix, 11.03.2025),
zudem wurden die WIP Patche zum ALGOL 68
Front‑End (gac)
am 01.01.2025 eingesandt
(leider wird es aber [noch? –
bzgl. GCC 15.1] nicht aufgenommen,
auch wenn offiziell algol68@gcc.gnu.org als
Mail‑Liste erlaubt und ebenso ein Git‑Branch
abgenickt wurde; vgl. Phoronix 09.03.2025; das neue Frontend
ga68 des Oracle Engineers Jose E. Marchesi
ist nun Bestandteil von GCC 16:
experimentell und als Default nicht aktiviert,
vgl. Phoronix 29.11.2025)
und es wird immer konkreter über eine Aufnahme
der Sprache Rust diskutiert🏗️ .
{Java / gjavac wurde
Ende 2000 aufgenommen; Java / GCJ wurde Ende 2016
wegen Mangels an Support entfernt
(ab GCC 7) –
GCJ war Ausschlag, dass Sun ihre Referenz-Implementierung
von Java als Open Source herausgab –
ggf. könnte Java‑Unterstützung
auch zurück kommen.}
Aktuell steht mit dem ersten Release
der frischen GCC 16‑Serie am 30.04.2026
der aktuelle Compiler zur Verfügung
(siehe Änderungen, neue Merkmale und Fixes sowie
Übersicht
der GCC‑Serien):
GCC 16.1 (siehe Phoronix‑Artikel sowie
LWN‑Artikel
mit Kommentaren, beide vom 30.04.2026;
neue Features sind z.B. C++20‑Standard
per Default, Unterstützung von AMD Zen 6 "znver6"
sowie von Arm AGI CPU, Algol 68‑Frontend,
HTML‑Ausgabe für Diagnose‑Unterstützung;
GCC 16.2 (Status‑Report vom 01.07.2026)
ist für Anfang August geplant und sollte
in Ubuntu 26.10 und Fedora 45
enthalten sein);
am 12.06.2026 stand das zweite
Bugfix‑Release der GCC 15‑Serie zur Verfügung:
GCC 15.3, zuvor
GCC 15.2 (siehe Phoronix‑Artikel vom 08.08.2025:
123 Bug‑Fixes);
zuvor kam wie geplant ab 18.04.2025
das nächste Release (nach GCC 15.0.1 Status Report
vom 17.04.2025 sowie der Ankündigung
des GCC 15.1‑RC):
GCC 15.1 bereit
(siehe Änderungen oder New C++ features in GCC 15;
leider ist aktuell die libstdc++-Version
noch nicht eingetragen worden – sollte (?)
aber libstdc++.so.6.0.34 sein;
das erste Bugfix-Release wird für
Mitte 2025 erwartet);
13 Monate später stand das dritte Bugfix‑Release
dessen Vorgängers
GCC 14.4
(am 26.06.2026) bereit,
GCC 14.3
(vom 23.05.2025 siehe Phoronix‑Artikel und Git‑Changes abzulösen;
davor kam das erste Bugfix‑Release
GCC 14.2
am 01.08.2024 heraus, siehe Phoronix‑Artikel;
zuvor kam das Major‑Release
GCC 14.1
vom 07.05.2024, vgl. Phoronix‑Artikel; libstdc++ 6.0.33) –
ebenso das etablierte zweite Bugfix‑Release
dessen Vorgängers:
GCC 13.4
bereit (vom 05.06.2025, vgl. Release‑Announcement;
davor 13.3 vom 21.05.2024, vgl. Phoronix‑Artikel;
zuvor 13.2 vom 27.07.2023, vgl. Phoronix‑Artikel;
13.1 vom 26.04.2023, vgl. LWN‑Artikel
bzw. Phoronix‑Artikel, oder die
Ankündigung bzw. Änderungen, bzw. die `New C features in GCC 13
from Red Hat Developer'),
während die jüngste Version des Vorgängers
nun keinen Support mehr bekommt ...
und alle weiteren Versionen
vorrangig historisch zu betrachten sind:
GCC 12.5
ist (vom 11.07.2025 ohne weitere Releases,
vgl. Phoronix‑Artikel;
12.4 vom 20.06.2024, siehe Phoronix‑Artikel;
12.3 vom 08.05.2023, siehe Phoronix‑Artikel;
12.2 vom 19.08.2022,
die auch in Kubuntu 22.10 STS
'Kinetic Kudu' enthalten ist, siehe Phoronix‑Artikel, 19.08.2022, Ankündigung von GCC 12.2 –
oder die Ankündigung von GCC 12.1
vom 06.05.2022, siehe Heise‑Artikel vom 10.05.2022,
Ankündigung, Phoronix‑Artikel, 06.05.2022 –
oder die spezielle Übersicht
der C++‑Neuerungen [RedHatDev, 25.04.2022];
und dieses sollte wohl in Kubuntu 22.04 LTS
enthalten sein [laut DistroWatch vor dem Release]),
dessen Vorgänger:
GCC 11.5
vom 19.07.2024 nun Ausläufercharakter besitzt
(siehe Release Notes; zuvor GCC 11.4 –
siehe Phoronix‑Artikel vom 29.05.2023,
davor GCC 11.3 –
siehe Phoronix‑Artikel, 21.04.2022;
zuvor strebte GCC 11.2 in die Distributionen
nach dem Release am 28.07.2021,
vgl. Phoronix‑Artikel;
davor GCC 11.1 vom 27.04.2021,
vgl. Ankündigung auf LWN sowie Artikel auf
Heise‑Online;
wesentliche Neuerungen stellte auch Phoronix am 25.04.2021 zusammen),
hier auch die Dokumentation der neuen GCC‑Vorgänger‑Fassung:
GCC 10.5 (letztes Update: Phoronix, vom 07.07.2023,
davor 10.4 vom 28.06.2022: Phoronix, 28.06.2022; zuvor 10.3
vom 08.04.2021: Phoronix, 08.04.2021; zuvor 10.2
vom 23.07.2020: Phoronix, 23.07.2020; zuvor 20.1
vom 07.05.2020: Heise‑Developer, Phoronix oder LWN‑Artikel –
oder die spezielle Übersicht
der C++‑Neuerungen [RedHatDev];
Version 10 hielt dann
in Kubuntu 20.10 STS mit 10.2.0 Einzug) bzw.
der alten Vorversion:
GCC 9.5
(vom 27.05.2022;
zuvor 9.4 vom 01.06.2021,
davor 9.3 vom 12.03.2020,
zuvor 9.2 vom 12.08.2019;
zuvor GCC 9.1),
ebenso im damaligen Kubuntu 20.04 LTS Focal in frischer Form enthalten
(als gcc 9.3.0) sowie
in Xubuntu 19.10 Eoan (als gcc 9.2.1),
ist auf Englisch im Internet verfügbar:
Online Documentation
(für Versionen 10.1 bis 2.95.3 –
sowohl in HTML‑Form als auch
im PDF‑Format; letzteres natürlich aus 📜TEX/LATEX‑Quellen erzeugt).
Die damals frisch erschienene GCC 10 verfügte
u.a. über einen `Static Analyzer' (vgl. Phoronix, 14.01.2020)
sowie als eine letzte Änderung
über die Option -std=c++20
nach Finalisierung von C++20 als DIS
('Draft International Standard, d.h. noch
ohne offizielle Zustimmung),
auch wenn die Arbeit dessen Implementierung in GCC
noch nicht abgeschlossen ist (siehe Phoronix, 16.02.2020).
Die in Entwicklung befindliche
(vgl. Entwicklungsplan von GCC; siehe Ende
<Strg+Ende>) nächste Fassung
GCC 17 (bitte warten ...,
nach Status‑Report
wurde der Entwicklungszweig kopiert und somit Stage 1
am 23.04.2026 begonnen, an die sich Stage 3
am 16.11.2026 und Stage 4 am 18.01.2027
anschließen wird,
der im kommenden Jahr 2027 GCC 17 wird
und für die generelle Entwicklung
zur Verfügung steht und als GCC 17.1
wohl um Mai 2027 veröffentlicht wird:
...).
Mit LLVM / Clang
(aktuelle Version 22.1.3 vom 06.04.2026;
vgl. frühere Major‑Version 20.1.0 vom 04.03.2025 [Phoronix, 04.03.2025 und dortigem
Vergleich zwischen
GCC 15 und LLVM Clang 20],
zuvor 19.1.0 vom 17.09.2024 [Phoronix, 17.09.2025],
davor 18.1.0 vom 06.03.2025 [Phoronix, 06.03.2025],
zuvor 17.0.1 vom 19.09.2023 [Phoronix, 19.09.2023],
davor 16.0.0 vom 18.03.2023
mit C++‑Default‑Standard GNU++17,
vgl. Phoronix‑Artikel, 18.03.2023)
gibt es zwar belebende Konkurrenz
(unter Intel x86_64 liegt er mit GCC dicht auf,
bei IBM POWER9 liegt Clang aber 20% zurück
[Phoronix, 23.07.2019] –
GCC erwies sich aber als schneller beim Kompilieren
von Linux für 64‑bit ARM und x86_64 [Phoronix, 02.09.2020; aktuelle Benchmarks
zwischen LLVM Clang und GCC bietet
für AMD EPYC Genoa der Phoronix‑Artikel, 30.05.2023];
viele Architekturen werden nicht unterstützt
[laut Homepage
produktiv für X86‑32, X86‑64
und ARM nutzbar];
aber Clang ist erste Wahl auf macOS –
so wie Microsoft Visual Studio erste Wahl
auf Windows ist),
aber weder ist Clang Freie Software wie GCC,
noch ist sie auf so vielen Plattformen und
für so viele Architekturen verfügbar
(und erst mit Clang 9/10 ist nach Unterstützung
von asm goto
der Mainline‑Kernel
für die x86_64‑Plattform
größtenteils compilierbar
[das amdgpu‑Problem
soll ab Kernel 5.4‑rc1 behoben sein],
zudem liegen die Benchmarks sehr dicht beisammen
[vgl. Phoronix, 12.09.2019];
Listen unterstützter Standards liegen aktuell
für C
sowie für C++ vor,
siehe auch Sprach‑Kompatibilität;
Härtung der beiden Compiler
LVM/Clang und GCC behandelt der LWN-Artikel;
dennoch ist ein generelles Übersetzen
des Linux‑Kernels mit Clang
trotz viel Bemühungen noch nicht gelungen;
wohl aber in einigen Bereichen
wie z.B. Android bereits etabliert).
Ebenso unterstützt GCC
die jüngsten Standards –
und auch wenn es ggf. verwundert:
C und C++ werden
ständig erweitert.
Ein aktueller GCC unterstützt C++17
(mit Parameter
-std=c++17
bzw. -std=gnu++17
für GNU‑Erweiterungen jenseits C++17
[Default ab GCC 11:
siehe Phoronix, 25.04.2021; ursprünglich
war sogar von GCC 10 die Rede];
einige Bibliotheksmerkmale fehlen allerdings oder
sind unvollständig; erste Spracherweiterungen
kamen in GCC 5),
das meiste von C++20
(mit Parameter -std=c++20
bzw. -std=gnu++20
für GNU‑Erweiterungen jenseits C++20
{bei GCC 9 oder GCC 8 -std=c++2a bzw. analog
-std=gnu++2a})
und zum Teil sogar C++23 (seit GCC 11
mit Parameter -std=c++2b bzw.
-std=gnu++2b
für GNU‑Erweiterungen jenseits C++23),
wobei als Status bei den beiden letzteren noch experimentell genannt wird,
da sie immer noch
recht jung [C++20, C++23] bzw. noch
in Entwicklung [C++26] sind –
wobei für GCC16 geplant ist, den Default
auf C++20 zu heben.
Der g++‑Default ist allerdings aktuell,
d.h. ab GCC 11,
C++17 (aka 201703L) mit GNU‑Erweiterungen, allerdings noch
C++14 (aka 201402L) mit GNU‑Erweiterungen
für GCC 6.1 bis GCC 10,
vor GCC 6.1 war es
C++98 (aka 199711L) –
wobei C++11 (aka 201103L)
ab GCC 4.8.1 vollständig
unterstützt wurde –
ggf. ist der nächste Default
C++20 (aka 202002L) oder
C++23 (aka 202xxxL, da noch
nicht verabschiedet).
[Entsprechend ist der GCC‑Default
für C nun (GCC 8.1)
bei C18 (aka 201710L),
zuvor (GCC 5.1.0)
bei C11 (aka 201112L),
anfänglich (GCC 4.9.4)
bei früher (aka undefined)
als C99 (aka 199901L)
oder auch C95 (aka 199409L);
jeweils mit Erweiterungen,
d.h. -std=gnu11
(hier sind die Korrekturen von C17|18
bereits enthalten;
sogar Teile des zukünftigen C22 werden bereits
mit -std=c2x
unterstützt).]
Der C++‑Default wird auf der Kommandozeile durch:
g++ -dM -E -x c++ /dev/null |
grep -F __cplusplus
ausgegeben (vgl. auch Default unterschiedlicher häufig verwendeter
C++‑Compiler).
[Analog wird der C‑Default
auf der Kommandozeile durch:
cc -dM -E -x c /dev/null | grep -F __STDC_VERSION__
ausgegeben.]
Einen genaueren Überblick über die
eingehaltenen Standards liefert C++ Standards Support in GCC,
eine entsprechende Übersicht vieler unterschiedlicher
C++‑Compiler liefert cppreference: compiler support.
GCC enthält die Standard‑Bibliothek, Compiler, Linker,
Assembler, Disassembler, ... –
dennoch werden zum Programmieren
noch Komponenten benötigt bzw.
können das Programmieren deutlich erleichtern,
was in den nächsten drei Unterabschnitten
behandelt wird.
𝔻 )
Die Programmiersprache D,
aktuell in Version 2.112.0 vom 07.01.2026,
mit objektorientierten,
imperativen sowie deklarativen / funktionalen Sprachelementen
wird seit 1999 von Walter Bright entwickelt,
der 2001 die erste Version (D1)
des Compilers veröffentlichte –
2007 wurde diese unter Mitwirkung
von Andrei Alexandrescu durch D2 abgelöst
(und entwickelte sich seither inkrementell
in über 100 Veröffentlichungen:
aktuell ist 2.098.1 vom 19.12.2021,
siehe Download bzw. Liste aller Versionen);
die D‑Standardlaufzeitbibliothek namens Phobos
wurde vom 2006 einsteigenden Andrei Alexandrescu
entwickelt.
D übernimmt die meisten Sprachmittel
der Sprache C,
verzichtet im Gegensatz zu C++ aber
auf die Kompatibilität dazu
(hält aber die ABI‑Kompatibilität,
so dass alle Programme und Bibliotheken,
ggf. über Funktionen und Wrapper,
nutzbar bleiben – die Anbindung von C++-Code
unterliegt dagegen Einschränkungen).
Programme können in D ohne Zeiger
geschrieben werden –
anders als Java ist es aber dennoch möglich,
Zeiger bei Bedarf nahezu wie in C zu benutzen
und so maschinennah zu programmieren.
D verfügt über Klassenvorlagen und
überladbare Operatoren, bietet Design by contract und Module und
besitzt Sprachmittel wie integrierte Unit‑Tests und
String Mixins;
Automatische Speicherbereinigung (Garbage Collector)
ist im Gegensatz zu z.B. C/C++ fester, wenn auch
prinzipiell optionaler Bestandteil der Sprache.
DMD, der Digital Mars D‑Compiler,
bildet die Referenzimplementierung,
von Walter Bright für die x86/x86-64‑Versionen
von Windows, Linux, macOS und FreeBSD erhältlich.
Der GNU D Compiler GDC verbindet
das Frontend von DMD mit dem GCC‑Backend
(ab GCC 9.1),
so wie der LLVM D Compiler LDC das Frontend
von DMD mit dem LLVM‑Backend verbindet.
Ebenso wurden die Compiler Dil und Dang
in D selbst programmiert, die kompatibel zu LLVM sind.
Mit Poseidon existiert sogar eine in D geschrieben IDE,
die Autovervollständigung sowie Refactoring unterstützt
und einen integrierten Debugger bietet –
unter den IDEs zum Programmieren in D
sei auch auf den D Extended EDitor hingewiesen.
GNU Debugger und WinDbg unterstützen D rudimentär
(Stand: Ende 2019).
Weitere Infos siehe Wikipedia
oder z.B. den Artikel
in Heise‑Magazinen: iX, 12/2019, S. 150, und iX, 13/2020, S. 26-29,
dem Buch Programming in D
by Ali Çehreli (inkl. kostenlosem ![[PDF-Icon]](images/pdf_icon.gif) PDF)
oder schlicht einer Internet‑Suche nach dem
Stichwort Dlang.
PDF)
oder schlicht einer Internet‑Suche nach dem
Stichwort Dlang.
🏗️ )
Rust ist eine recht neue, von Mozilla Research
entwickelte und 2010 erschienene Sprache
(erste stabile Version 1.0 am 15.05.2015;
aktuell ist
Rust 1.96.0 vom 28.05.2026,
siehe auch rust‑lang.org;
vgl. auch frühere Ankündigungen zu
Rust 1.95.0 vom 16.04.2026,
Rust 1.94.0 vom 05.03.2026,
Rust 1.93.1 vom 12.02.2026,
Rust 1.93.0 vom 22.01.2026,
Rust 1.92.0 vom 11.12.2025,
Rust 1.91.1 vom 10.11.2025,
Rust 1.91.0 vom 30.10.2025,
Rust 1.89.0 vom 07.08.2025,
Rust 1.88.0 vom 26.06.2025,
Rust 1.87.0 vom 15.05.2025,
Rust 1.86.0 vom 03.04.2025,
Rust 1.85.1 vom 18.03.2025,
Rust 1.85.0 vom 20.02.2025,
Rust 1.84.1 vom 09.01.2025,
Rust 1.84.0 vom 09.01.2025,
Rust 1.83.0 vom 28.11.2024,
Rust 1.82.0 vom 17.10.2024,
Rust 1.81.0 vom 05.09.2024,
Rust 1.80.0 vom 25.07.2024,
Rust 1.79.0 vom 13.06.2024,
Rust 1.78.0 vom 02.05.2024,
Rust 1.77.0 vom 21.03.2024,
Rust 1.76.0 vom 08.02.2024,
Rust 1.75.0 vom 28.12.2023,
Rust 1.74.1 vom 07.12.2023,
Rust 1.74.0 vom 16.11.2023,
Rust 1.72.0 vom 24.08.2023,
Rust 1.71.0 vom 13.07.2023,
Rust 1.70.0 vom 01.06.2023,
Rust 1.69.0 vom 20.04.2023,
Rust 1.68.0 vom 09.03.2023,
Rust 1.67.0 vom 26.01.2023;
vgl. auch Heise‑Developer zu: Rust 1.66 (offizielle Ankündigung), Rust 1.65 (offizielle Ankündigung bzw. LWN‑Bericht),
Rust 1.64 (offizielle Ankündigung), Rust 1.63 (offizielle Ankündigung), Rust 1.62 (offizielle Ankündigung), Version 1.61, Rust 1.60, Version 1.59, Rust 1.58, Version 1.57 sowie Version 1.45, Heise‑Developer, 17.07.2020 oder iX 13/2020, S. 16-19).
Diese Programmiersprache, die sicher, nebenläufig
und praxisnah sein sollte, habe ich zwar weiter unten
nicht als eine meiner Empfehlungen
aufgeführt, wohl aber bzgl. der Ranglisten der Programmiersprachen
mit deutlichem Vorsprung vor Go herausgehoben.
Eine der Gründe liegt am immer wieder anvisierten
möglichen Einsatz von Rust für Linux-Systemtreiber
(siehe z.B. LKML
vom 27.04.2019 oder den LWN‑Beitrag vom 29.08.2019
zur positiven Aufnahme zukünfigen Codes in Rust
durch Greg Kroah‑Hartman),
was ebenfalls deutlich
in einer wissenschaftlichen Studie anklang,
nach der die meisten Sicherheitsprobleme
in den Treibern zu finden seien
(siehe Preprint: arxiv.org/1909.06344
vom 13.09.2019).
Und in 2020 scheint dies nun konkretere Formen
anzunehmen (vgl. Heise‑Developer, 14.07.2020)
und wird auch für den zukünftigen Gebrauch
in Mesa diskutiert (vgl. Phoronix, 02.10.2020).
Ende 2019 gab es erneute Diskussionen,
ein offizielles Frontend für Rust in GCC
einzuführen – bisher gibt es lediglich
Out‑Of‑Tree‑Fassungen (siehe den Phoronix‑Artikel vom 03.12.2013 sowie vom 29.05.2021 zu ersten Vorbereitungen
zur Aufnahme in GCC),
wobei eine Aufnahme auch zur allgemeinen Sprachdefinition
zu begrüßen wäre
(vgl. Phoronix‑Artikel vom 28.12.2019).
Wenn die Rust‑Entwickler mitzögen, könnte so
das Henne‑Ei‑Problem elegant vermieden werden.
Das Projekt 'rustc_codegen_gcc' von Antoni Boucher
kann vom existierenden rustc‑Frontend
geladen werden, so aber von GCC profitieren, so dass
mehr Architekturen zur Verfügung stehen und ebenso
die Optimierungen von GCC (siehe LWN‑Ankündigung,
01.04.2022) –
ein bedeutender Meilenstein auf dem Weg,
einen auf GCC basierenden Compiler als Alternative zum
LLVM‑basierten offiziellen Compiler anzubieten (siehe Phoronix‑Artikel, 02.04.2022).
Offenbar schreitet das Projekt gut voran, so dass
man hofft, bis Nov. 2022 gültigen Rust‑Code
mit Rustc Version ~1.4 zu unterstützen und
libcore, liballoc sowie libstd
wiederzuverwenden, so dass dies noch in GCC 13
aufgenommen werden könnte –
borrow checker feature und
proc macro crate sind dann in einem
anschließenden 6‑Monate‑Projekt geplant
(siehe Heise‑Online, 01.07.2022, LWN 29.06.2022 bzw. Phoronix‑Artikel, 27.06.2022). Bereits am 11.07.2022 stimmte
das GCC Steering Committee für die Aufnahme
des Rust Frontends in GCC (als GCC Rust;
siehe LWN‑Information bzw. Phoronix‑Artikel,
beides vom 11.07.2022) – und am 27.07.2022 wurde der Patch Set
in anfänglicher Version 1
für das GCC‑Front‑End eingesandt
(siehe Phoronix‑Artikel, 28.07.2022).
Vor diesen ersten beiden Ankündigungen zu den
GCC‑Annäherungen bzgl. Rust
erklärte Linus Torvalds auf der Open Source
Summit North America (OSSNA) 2022 in Austin,
Texas, dass Rust für Linux schon im
nächsten Merge‑Fenster, d.h. in Linux 5.20
(nun 6.0 genannt),
aufgenommen werden könnte
(siehe Heise‑Online, 27.06.2022, LWN‑Artikel,
28.06.2022, bzw. Phoronix‑Artikel, 21.06.2022).
Miguel Ojeda hat die neueste Patch‑Serie v8
für Linux eingereicht, der die Infrastruktur
zur Programmiersprache Rust in 43,6 k Zeilen
implementiert inkl. anfänglichem Beispielcode
zum Linux Kernel (vgl. Phoronix‑Artikel, 02.08.2022).
Auf Ratschlag von Greg Kroah‑Hartman
wurde für Rust eine minimale Basis
von 12,5 k Codezeilen als 'Rust for Linux v9' eingereicht –
um eine Chance zu haben, diese Basis mit Linux 6.0
noch einbauen zu können, da es nicht mehr
über viele Kernel‑Subsysteme verteilt ist ...
Der Rest des mehr als 3× so großen v8
wird dann in mehreren Patches in folgenden Kerneln
an die entsprechenden Maintainer geschickt und sukzessive
ergänzt, wie es bei der Linux‑Entwicklung
üblich ist, damit der Review‑Prozess
handhabbar bleibt (siehe auch Phoronix‑Artikel, 05.08.2022).
Dennoch muss die Rust‑Infrastruktur nun
mindestens bis Linux 6.1 bzgl. der Aufnahme
warten – und nach Einsenden
der 10. Patch‑Version am 27. Sep. 2022
wurde es mit Linux 6.1‑rc1 aufgenommen
(als initiale Entwicklungsumgebung
mit 12,6k SLOC im 1. ReleaseCandidate
vom 16.10.2022).
Vielleicht wird schon für 6.2-rc die nächste Sammlung
von "Rust for Linux"‑Patchen
aufgenommen werden (vgl. Phoronix‑Artikel, 11.11.2022 bzw. 11.12.2022).
Aktuell konzentriert sich alles
auf die x86_64‑Architektur, aber bald soll
auch AArch64 / ARM64 die Rust‑Umgebung
nutzen können, wobei Arm dabei mithilft (vgl. Phoronix‑Artikel, 25.01.2023).
Auch für 6.3-rc wurde bereits
die nächste Sammlung
von "Rust for Linux"‑Patchen
Linus zugeschickt (vgl. Phoronix‑Artikel, 13.02.2023),
mit weiteren Ergänzungen des Kern‑Bereichs, um bald
auch die ersten Rust‑Module aufnehmen zu können.
Linux 6.5 verwendete die Rust 1.68.2 Toolchain,
wobei diese nun häufiger geupdated werden soll,
wobei dies ab einer sinnvollen Reife durch eine
verpflichtende minimale Ziel‑Version
(MSRV: Minimum Supported
Rust Version genannt)
für den Linux Kernel ersetzt werden soll
(vgl. Phoronix‑Artikel, 06.12.2022).
Dies wird nun umgesetzt, wobei als erstes Update
mit Linux 6.6 die Toolchain auf den Stand
von 1.71.1 gehoben wurde (vgl. Phoronix‑Artikel, 30.07.2023 bzw.
25.08.2023) –
zudem wurde zeitgleich bereits die Umstellung
auf 1.72 begonnen, angedacht für Linux 6.7
oder später –
wobei mit Linux 6.7 'Rust WQ Abstractions',
'Android Kernel Builds' wie auch
ein Toolchain Upgrade auf Rust 1.73 vorgenommen wurde
(vgl. Phoronix‑Artikel, 31.10.2023) –
und mit Linux 6.8 wurde die Toolchain
auf Rust 1.74.1 gehoben (vgl. Phoronix‑Artikel, 08.01.2024) –
mit Linux 6.9 wurde die Toolchain
auf Rust 1.76 gehoben (inkl. zwei verwendeter
Bereiche, die nun weiter stabilisiert wurden;
vgl. Phoronix‑Artikel, 10.03.2024),
wobei für Linux 6.10 ein Update
auf 1.78 geplant und ausgeführt wurde (vgl. Phoronix‑Artikel, 02.04.2024) –
nun wurde am 01.07.2024 der anvisierte Schritt
vorbereitet, eine minimale Rust‑Version
(aktuell Rust 1.78)
vorzuschreiben und spätere zuzulassen,
was durch ständige Tests untermauert wird:
möglicher Weise werden diese Patche
schon in Linux 6.11 aufgenommen (vgl. Phoronix‑Artikel, 01.07.2024).
Zudem gibt es nun auch eine formatierte Rust‑Kernel‑Dokumentation
(siehe LWN‑Artikel
vom 18. Aug. 2024).
[Zur Info:
Der aktueller Stand der Entwicklung
von Rust‑for‑Linux ist auf github
ersichtlich – siehe auch README.md.]
Zudem wurden die GCC Rust Patches (v3)
vom gccrs Projekt von Philip Herron
bereits für GCC 13 eingereicht –
und mit Rust Patches v4 steht nun der Aufnahme
nichts mehr im Wege
(vgl. Phoronix‑Artikel, 06.12.2022, sowie LWN‑Bericht, 07.12.2022, mit weiteren
Hintergrundinformationen) und wurde bereits
in GCC 13 eingebaut
(vgl. Phoronix‑Artikel, 13.12.2022),
aber es bleibt eine sehr frühe Fassung,
mit der die Kernbibliothek noch nicht
übersetzt werden kann.
Weitere Informationen über den aktuellen Stand
des GCC‑Front‑Ends wurden auf der FOSDEM
Entwickler‑Konferenz 02/2023 präsentiert
(siehe Slide Deck und Phoronix‑Artikel, 13.02.2023)
und zwei Monate später wurde über ein Update des gccrs Frontend auf LWN berichtet.
Mittlerweile wurden beinahe 900 neue Patche
für GCC 14 eingereicht (Phoronix‑Artikel,
16.01.2024; vgl. auch Monthly Status Reports).
Aber es gibt mittlerweile aktuelle Berichte
zum Stand von gccrs:
Den LWN‑Artikel vom 01.10.2024 "An update
on‑gccrs development" sowie
"gccrs:
An alternative compiler for Rust"
(Rust‑lang Block vom 07.11.2024).
[Zur Info reimplementiert das gccrs Projekt
rustc in C++, wohingegen das rustc_codegen_gcc Projekt
rustc so erweitert, dass es GCC
als Backend verwendet.
Der Blog‑Beitrag zur Frage,
ob Rust ein Standard werden muss oder eine Spezifikation
ausreicht, weist auf den aktuell schwierigen Weg
zu einem professionellen Rust‑Gebrauch hin –
ohne den ein sinnvoller Einsatz von Rust
in wesentlichen Projekten wie Linux oder Mesa
kaum denkbar wäre, vgl. auch LWN‑Artikel.]
Linker von GCC
Bei einer Compiler‑basierten Sprache wie C
oder C++ werden zwei Phasen benötigt:
in der ersten werden Quelldateien
zu Objektdateien kompiliert,
in der zweiten erzeugt der Linker aus allen
Objektdateien eine einzige ausführbare Datei bzw.
eine Shared Library.
Dabei wirkt der Vorgang aus einem Guss,
da man lediglich den Compiler aufruft,
der nach dem Compiler‑Durchlauf
den Linker startet.
Somit wird der Linker im Build‑Programm
wie make festgelegt – typisch per
Umgebungsvariable – oder dem Compiler
als Flag mitgeteilt.
Bei installiertem GCC muss man sich
im ersten Moment keine Gedanken um einen Linker machen ... dennoch ist dieser
ein wichtiger Bestandteil und somit
hier eine Übersicht der von GCC
verwendeten Linker für 🐧GNU/Linux:
- ld – der klassische GNU‑Linker und
Bestandteil der GNU Binary Utilities
(vgl. 📍binutils weiter unten);
- gold – ein anfänglich
von Google entwickelter Linker,
der über das Compiler Flag -fuse-ld=gold
oder über makefile, d.h. über Setzen
der LD‑Umgebungsvariable auf ld.gold,
verwendet werden kann; er beschränkt sich
auf das ELF‑Binärformat, nutzt also nicht
wie ld die BFD‑Bibliothek, ist aber
wie der ld Bestandteil der GNU Binary Utilities
(vgl. 📍binutils [ab 2.19]
weiter unten);
- lld – der Linker
der LLVM‑Compiler‑Architektur,
der ELF, PE/COFF, Mach‑O und WebAssembly
unterstützt und hauptsächlich von Rui Ueyama
entwickelt wurde;
- mold – das 'new kid
on the block', wie lld
von Rui Ueyama entwickelt, wobei mold
alle Geschwindigkeitsrekorde brach
(auf Grund schneller Algorythmen,
effizienter Datenstrukturen sowie
höchster Parallelisierung)
und ab GCC12 über das Compiler Flag
-fuse-ld=mold (und bei
vorigen GCC‑Versionen über
-B/usr/local/libexec/mold)
verwendet werden kann und seit Meson 0.63.0 vom 03.07.2022
unterstützt wird (siehe Meson; auswählbar über
CC_LD bzw. CXX_LD für Clang und
GCC >= 12.0.1);
mold Version 1.0 kam Ende 2021,
1.1 am Anfang 2022 –
kurz darauf 1.1.1, im April 1.2,
im Juni 1.3.0, Ende September 1.5,
Mitte Oktober 1.6, Mitte November 1.7,
Ende Dezember 2022 1.8,
Anfang Januar 2023 1.9,
Ende Januar 1.10
[bzw. Bugfix 1.10.1],
Mitte März 1.11,
Ende Juli 2023 2.0,
Mitte August 2023 2.1,
Ende September 2023 2.2,
Mitte Oktober 2023 2.3,
Ende November 2023 2.4,
Mitte März 2024 2.30.0,
Anfang Mai 2024 2.31.0,
Anfang Juni 2024 2.32.0,
Anfang August 2024 2.33.0,
Ende September 2024 2.34.0,
Anfang Dezember 2024 2.35.0,
Anfang Januar 2025 2.36.0,
Anfang März 2025 2.37.0,
Ende April 2025 2.38.0,
Mitte Mai 2025 2.39.1,
Ende Mai 2025 2.40.0,
Anfang Juni 2025 2.40.1,
Ende Juli 2025 2.40.3,
Mitte April 2026 2.41.0,
(vgl. Phoronix‑Artikel, 21.12.2021, 21.02.2022, 08.03.2022, 15.04.2022, 18.06.2022, 27.09.2022, 19.10.2022, 13.11.2022, 26.12.2022, 06.01.2023, 20.01.2023, 16.03.2023, 26.07.2023, 13.08.2023, 24.09.2023, 18.10.2023, 30.11.2023, 15.03.2024, 03.05.2024, 09.06.2024, 07.08.2024, 25.09.2024, 08.12.2024, 09.01.2025, 06.03.2025, 26.04.2025, 12.05.2025, 26.05.2025, 09.06.2025, 30.07.2025,
bzw. 13.04.2026; vgl. Release‑Liste
mit Datum‑Angaben per github‑Tags).
Fehlersuche im Binary
mit dem Debugger GDB
Wenn ein Binary nicht das tut, was es soll,
hat man meist als Autor eine Idee und
findet das Problem im Quelltext –
ggf. mit ein paar Codeveränderungen und Testen (im sogenannten 'Edit – Compile – Test' -
Zyklus).
Ist es komplizierter, so hat man
viele Möglichkeiten, sich dem Problem
zu nähern,
die zum Teil beim erzeugten Binary
und dem Umgang mit diesem bereits skizziert sind.
Eine besondere Rolle fällt dabei dem Debugger (d.h. beim 'Edit – Compile – Debug' -
Zyklus) zu , im GNU‑Projekt gleichbedeutend
mit Debugger GDB,
dessen aktuelle Version GDB 15.1 am 07. Juli 2024
herauskam (zuvor GDB 14.2 am 03. März 2024;
davor GDB 14.1 am 03. Dez. 2023, vgl. Phoronix‑Artikel vom 03.12.2023;
zuvor LWN‑Artikel zu GDB 13.1
vom 20.02.2023 oder Phoronix‑Artikel vom 19.02.2023;
davor erschien am 01. Mai 2022 GDB 12.1,
vgl. Ankündigung;
zuvor wurde GDB 11.2 am 16. Jan. 2022
veröffentlicht, vgl. Ankündigung; die vorige Version ist
GDB 11.1 vom 12. Sep. 2021, siehe Ankündigung auf LWN,
hier der generelle Link zur letzten GDB‑Ankündigung durch GNU;
die vorige Version 10.2 stammt vom 25.04.2021,
das erste Bugfix‑Release 10.1 wurde auf LWN angekündigt,
diese und andere Versionen wurden auch
in Phoronix‑Artikeln behandelt:
10.1 am 24.10.2020 sowie
die u.a. Multi‑Target Debugging bringende vorige
Version 9 am 11.01.2020;
siehe auch Online‑Dokumentation).
GDB unterstützt die Programmiersprachen:
Ada, Assembler, C, C++, D, Fortran, Go, Objective-C, OpenCL,
Modula‑2, Pascal und Rust.
Beim Debuggen von C‑ und C++‑Programmen
kann zusätzlich zu GDB auch rr
verwendet werden, da mit Hilfe des rr‑Projekts
das gesamte Leben eines C/C++‑Programms untersucht
werden kann – sehr nützlich, wenn ein Bug
nicht sofort zu einem Fehlverhalten führt
(siehe Red Hat Developer, 03.05.2021).
Beim aktuellen Stand, den diese Webseite
vermitteln soll, ist der Einsatz von Debuggern
kaum nötig –
ich werde hierzu aber mit hoher Wahrscheinlichkeit
in Zukunft weitere Erläuterungen ergänzen.
Umgang mit Quelltexten:
Editoren und IDEs
Was zum Programmieren
aber in jedem Fall benötigt wird,
ist ein Editor oder eine IDE
(Integrated Development Environment),
um den Quelltext eingeben zu können.
Als Editor empfehle ich wie immer 🐧vim
(siehe auch Vim 9‑Artikel
[Heise‑Online, 29.06.2022]),
wobei bei Programmierern
eher emacs (echter Bestandteil
des GNU‑Projekts – ebenso IDE;
siehe Homepage bzw. Artikel von Heise‑Online vom 01.08.2023
zum neuen Emacs 29.1)
beliebt ist.
Beide Editoren haben eine steile Lernkurve,
wachsen aber hervorragend mit.
Einfache Editoren haben den entscheidenden Nachteil,
dass man später umsteigen muss;
wer aber dennoch erst einmal diese Hürde
nicht nehmen will, sei auf
joe, gedit, jedit oder kate verwiesen.
Eine IDE würde ich zu Anfang nicht empfehlen,
weil man dadurch eher abgelenkt wird und sich ggf.
oberflächliches Vorgehen einschleift –
genauso wie ich einen 📜WYSIWYG‑TEX/LATEX‑Editor ablehne.
Dennoch hier einige Beispiele für eine IDE
für C/C++‑Projekte:
GNAT Programming Studio (GNAT,
GPS Homepage),
Code::Blocks,
Lazarus,
MonoDevelop,
NetBeans,
Eclipse CDT (C/C++ Development Tooling),
CodeLite,
Bluefish,
Geany,
Anjuta (GNOME),
Qt Creator (Homepage of qt.io, Phoronix‑Artikel zur Version 12
vom 23.11.2023, Phoronix‑Artikel zur Version 11
vom 20.07.2023, Phoronix‑Bericht zur Version 10
vom 29.03.2023 bzw. Phoronix‑Bericht vom 14.10.2021),
KDevelop (KDE; Homepage,
Phoronix‑Bericht vom 07.09.2020 oder
vom 02.02.2020 oder auf Deutsch den Heise‑Bericht
über die vorige Version 5.5 bzw.
06.08.2019 Phoronix‑Bericht
oder auf Deutsch den Heise‑Bericht
über die alte Version 5.4 – bzw. auf Deutsch den Heise‑Bericht
vom 08.09.2020 über die aktuelle Fassung 5.6 mit frischem Bugfix‑Release 5.6.1
vom 11.12.2020 – vgl. Neuigkeiten).
Automatisierte Erstellung von Binaries:
Makefiles als Steuerdatei
des Utilitys make
Sinnvoll ist aber der Gebrauch
eines Makefiles
(das vom Utility make verwendet wird; GNU make ist aktuell
in Version 4.4.1 (26.02.2023) verfügbar und
erschien am 31.10.2022 in Version 4.4,
vgl. Phoronix & LWN;
zuvor am 19.01.2020 in Version 4.3, vgl. Phoronix & LWN;
siehe dessen Einsatz unterhalb des Makefile‑Beispiels;
vgl. GNU Autoconf),
der die nötigen Eingaben
auf ein sinnvolle Maß reduzieren kann
(vgl. Eine Einführung in Makefiles,
kleine Einführung für C und Makefiles,
O'Reilly-Einführung in Makefiles,
GNU make Manual) –
hier ein sinnvolles kleines Beispiel für Makefile:
# ******************************************************************************
# * 'Makefile' des Verzeichnisses '~/mycpp/jmb/' *
# * *
# * J.M.B. [URL: https://www.jmb-edu.de/cpp_programming.html#makefileexamp] *
# * *
# * Lizenz: (c) 2019 unter GPLv3: https://www.gnu.org/licenses/gpl-3.0.txt *
# * *
# * Erstellung: 05.08.2019 *
# * *
# * Letzte Umgestaltung: 04.09.2019 (Phase 2; vgl. Phase 1 vom 08.08.2019) *
# ******************************************************************************
# * Dafuer sorgen, dass 'all' und 'clean' auch dann ausgefuehrt werden,
# wenn die jeweils entsprechende Datei existieren sollte:
.PHONY: all clean exampd exampf example_debug example c cf
# * Beim Hilfstext nicht durch doppelte Ausgabe verwirren, also das Kommando
# nicht vor der Ausfuehrung ausgeben:
.SILENT: info help h
# * Definitionen von sinnvollen Compiler-Flag-Kombinationen als Variable
# (hier ist noch viel Raum fuer Verbesserungen - nur ein Anfang):
# o Debug Modus: optimierte Debugging-Faehigkeit mit allen Standard- sowie
# allen Extra-Warnungen (zum Lernen beim Edit-Compile-Debug-Zyklus):
cppflagsd = -Og -Wall -Wextra
# o Space Modus: optimiert bzgl. Groesse und alles von -O2, das dem nicht
# zuwider laeuft (falls man es mal brauchen sollte ;):
cppflagss = -Os
# o Final Modus: optimiert haerter bzgl. Kompilierzeit und Geschwindigkeit
# des Binarys.
cppflagsf = -O2
# * Fuer Namensgebung der Backup-Datei Datum und Zeit als String besorgen:
bckdate := $(shell date +%Y%m%0e%0k%M%S)
bckname := ~/Downloads/mycpp_jmb_$(bckdate).tgz
humdate := $(shell date +%a.,\ %0e.%m.%Y,\ %0k:%M:%S)
humdatedate := $(shell date +%a.,\ %0e.%m.%Y)
humdatetime := $(shell date +%0k:%M:%S)
# ** Das nun kommende erste Target wird ausgefuehrt, wenn 'make' ohne
# Argument, d.h. der Angabe des Targets, aufgerufen wird:
# * Hilfstext (zur Uebersicht, was alles gemacht werden kann; siehe Screenshot unten):
info help h:
-echo "Zur Zeit sind die folgenden Parameter moeglich: ^***************"
-echo " ep = ed = edit = e: * Hilfs-Text *"
-echo " Quelltext des Programms mit vim editieren, * zu 'make' *"
-echo " em: * von J.M.B. *"
-echo " Editieren von 'Makefile' mit vim, ^*********** *"
-echo " exampd = example_debug = c: * *"
-echo " Kompilieren & Linken von 'example_debug' & 'ls -l' vom Binary, * *"
-echo " exampf = example = cf: * *"
-echo " Kompilieren & Linken von 'example' und 'ls -l' vom Binary, * *"
-echo " all {= exampd & exampf}: * *"
-echo " Erzeugen beider Binaries: 'example_debug' & 'example', * *"
-echo " r: * *"
-echo " Aufrufen von 'example_debug args' & Fehlercode ausgeben, * *"
-echo " run: * *"
-echo " Aufrufen von 'example args' - danach Fehlercode ausgeben, * *"
-echo " clean: * *"
-echo " Hausputz (: 'example_debug' loeschen), * *"
-echo " superclean: * *"
-echo " Fruehlingsputz (% 'clean' + loeschen von 'example'), * *"
-echo " backup = bck **** [jmb-edu.de] * *"
-echo " Erstellen einer tgz-Sicherung, * **************** *"
-echo " help = h = info = '' {d.h. ohne Target}: * Have Fun with GNU! *"
-echo " Diesen Hilfstext ausgeben. ***********************"
-echo " == GNU 'make' ${MAKE_VERSION} gestartet am $(humdatedate), um $(humdatetime) Uhr ! =="
# * Was man unter `mach alles' verstehen soll (z.B. mehrere Binaries bauen;
# dieses Target ist zumeist das erste und wird bei 'make' ausgefuehrt):
all: exampd exampf
# * Sprungpunkt/Target fuer das Programm (Name und was damit passieren soll):
# -a) Optimiert fuer optimale Debbuging-Faehigkeit, allen Standard-
# sowie den Extra-Warnungen (zum Lernen beim Edit-Compile-Debug-Zyklus):
exampd c example_debug: example.cpp
-g++ $(cppflagsd) example.cpp -o example_debug
-ls -l example_debug
# - b) Optimiert fuer Kompilierzeit und Geschwindigkeit des Binarys:
exampf cf example: example.cpp
-g++ $(cppflagsf) example.cpp -o example
-ls -l example
# ... fuer weitere Verbesserungen siehe z.B.:
# https://developers.redhat.com/blog/2018/03/21/compiler-and-linker-flags-gcc/
# * Editieren:
# o ... des Programm-Quellcodes:
ep ed edit e:
-vim example.cpp
# o ... des Makefiles:
em:
-vim Makefile
# * Binary aufrufen, danach Fehlercode auslesen (0 = OK; sonst = KO):
r:
-./example_debug $(filter-out $@,$(MAKECMDGOALS)); echo "Fehlercode: "$$?" !"
# * Fuer andere als die ausgewiesenen Targets mache nichts
# (wegen r/run-Optionen noetig, sie sonst je eine Fehlermeldung gaeben) -
# Vorsicht: 'make quark' macht nichts - auch keine Fehlermeldung!:
%:
@:
run:
-./example $(filter-out $@,$(MAKECMDGOALS)); echo "Fehlercode: "$$?" !"
# * Waere Compilieren und Ausfuehren gewuenscht, dies auskommentieren:
#cr: c r
# * Hausputz (Problemreste und Debug-Binary werden geloescht):
clean:
-rm -f core *.o *.bak *~ example_debug
# * Fruehlingsputz (auch das finale Binary wird nun geloescht):
superclean: clean
-rm -f example
# * Sicherung (als gezipptes tar-Archiv):
backup bck: clean exampd
-echo "Sichere in: '$(bckname)' ..."
-cd .. ; tar cfvz $(bckname) jmb/ ; cd jmb
# Zu beachten ist, dass nach "TARGET:" bzw. am leeren Zeilenanfang Tabs
# stehen muessen - Leerzeichen funktioniert nicht - ebenso zwischen
# multiple targets, die von einem anderen (hier 'all' oder 'bck')
# aufgerufen werden!
# Somit darf man auch nicht Copy&Paste machen (Blanks werden dann durch
# Leerzeichen ersetzt), sondern kopieren oder ueber 'tar' sichern ...
# ******************************************************************************
# * Das war's ... Viel Spass beim eigenen Experimentieren und Programmieren ! *
# ******************************************************************************
Nun kann mit make example
(oder make example_debug;
per make all
wird beides gemacht) das Beispielprogramm example.cpp übersetzt werden,
der Hausputz macht aktuell noch wenig
(da core, *.o und *.bak nicht existieren;
lediglich example_debug
würde gelöscht),
make superclean
löscht zusätzlich das Binary
(d.h. die ausführbare Datei
in Maschinensprache),
und make backup
erstellt ein Backup des Verzeichnisses jmb.
Noch wirkt es nicht wie eine notwendige Ersparnis,
aber schon aufwendig ausgeklügelte Compiler-Flags
(vgl. insb. Optimierungs-Optionen oder
Warnungen – oder auch die Red Hat Empfehlungen für Compiler-
und Linker‑Parameter der GCC)
oder mehrere zu übersetzende Module bringen dadurch
eine enorme Erleichterung sowie Ordnung, Dokumentation
und Übersicht.
Der Hauptzweck von make
liegt im automatischen Erzeugen lauffähiger Programme,
bei der ggf. viele Dateien übersetzt und
gelinkt werden müssen, d.h. Compiler und Linker
stehen im Zentrum.
Zudem hat man heute viele Auswahlmöglichkeiten,
welche Anforderungen das Binary erfüllen soll.
Diese werden über Parameter,
den sogenannten Compiler‑Flags,
GCC mitgeteilt.
Wenn man Fehler finden will, sollten Debugginghilfen
eingebaut sein, die sich eher nachteilig
auf die Größe und/oder die Ablaufgeschwindigkeit
auswirken werden.
Daneben kann man die Ablaufgeschwindigkeit
optimieren – soweit,
dass man ggf. bei einigen Binaries Fehler provoziert
(d.h. nicht nur harte sondern sogar
agressive Optimierung –
ohne Rücksicht auf Verluste).
Im Gegenzug können auch seltene Ausnahmebedingungen
abgefangen werden oder Angriffsziele maskiert bzw.
geschützt werden,
was als Härtung des Codes bezeichnet wird –
im Gegensatz zur Härte der Optimierung,
die bei hart sozusagen im gelben Bereich und
bei agressiv im roten liegt (der ggf.
im Beispiel von schnellen 🕹️Spielen mit nicht mehr
perfekter Grafik durchaus akzeptabel sein kann,
bei einem Dateisystem oder einer Datenbank
mit fehlerhafter Verarbeitung aber
inakzeptabel wäre).
Diese Optimierung wird hier grob per Flags
in den Zeile 22‑32 gesteuert und dann
in Zeilen 75‑87 umgesetzt.
Aber man sieht, dass man den Namen nicht mehr
kennen muss;
man geht ins Projektverzeichnis,
editiert die Quelldatei (wenn es nur eine ist,
sonst braucht man geeignete Label)
mit make edit,
übersetzt die Codes mit make all und ruft zum Test
das Binary mit make run auf
(bzw. make r;
vgl. zugehöriges Programm).
Der Bereich von Zeilen 99‑110
wurde am 23.08. ergänzt, um dem Binary
auch einen oder mehrere Parameter
beim Aufruf mitgeben zu können.
D.h. statt im aktuellen Verzeichnis
./example 2147483646 einfach
make r 2147483646;
bei negativen Zahlen muss man ‑‑ als
erstes Argumen von make
verwenden, damit das führende - nicht als Argument
von make missverstanden wird,
d.h. anstatt ./example ‑5 aufzurufen
(vgl. Programm-Output unten),
kann man nun auch
make ‑‑ run ‑5 eingeben.
Wer keine Parameter von make benötigt, kann auch alias make='make ‑‑'
in eine ~/.alias Datei
einbauen und von ~/.profile
durch die am Ende anzufügenden Zeilen:
if [ -f "$HOME/.alias" ]; then
. "$HOME/.alias"
fi
automatisch aufrufen lassen.
Dann funktioniert auch make run ‑5.
Das Makefile steht unten
mit dem Beispielprogramm example.cpp
und den resultierenden Binarys example
und example_debug zum direkten
Download bereit.
Hier die Ausgabe der Hilfsseite
von der aktuellen Makefile‑Datei,
die mit make info
(oder einfach mit make) ausgelöst wird:
Die Vorteile, die 🐧GNU/Linux, GCC und die GNU‑Kette
der Hilfswerkzeuge bieten,
sollten mit diesen Argumenten schon klar belegt sein.
Build‑System: Meson / mesonbuild
Während make das klassische Minimum darstellt
und für Einsteiger und auch
für Fortgeschrittene Projekte
empfehlenswert sein kann, sind Build‑Systeme
eher maximiert angelegt.
Diese sind Software‑Pakete, die Programmquellcode und
Abhängigkeiten wie Bilder und Icons zu einem
ausführbaren Programm kompilieren und linken.
Heute beliebt ist das Open Software‑Paket
Meson,
das die Betriebssysteme GNU/Linux, macOS
und Windows – die Compiler GCC, LLVM/Clang,
Visual Sudio und andere – viele Programmiersprachen
wie C, C++, D, Fortran, Java und Rust
unterstützt (Offizielle Website; erschienen
im Jahr 2013 – aktuell ist die Meson‑Version 1.10.0
vom 08.12.2025, vgl. auch Release Notes und Phoronix‑Artikel
zu früheren Versionen wie Meson 1.9.0, Meson 1.8.0 (Phoronix-Artikel) vom 28.04.2025, Meson 1.6.0 vom 20.10.2024, Meson 1.2.0 vom 08.08.2023, Meson 1.1.0 vom 10.04.2023, Meson 1.0.0 vom 23.12.2022 bzw. Meson 0.64 vom 06.11.2022;
siehe mold).
Versionsverwaltung und
verteilte Versionsverwaltung: git
Eine Versionsverwaltung (Englisch:
Version Control System, VCS) ist ein System,
das zur Erfassung von Änderungen an Dokumenten
oder Dateien verwendet wird.
Alle Versionen werden in einem Archiv mit Zeitstempel
und Benutzerkennung gesichert und können später
wiederhergestellt werden.
Typisch sind die Aufgaben:
Protokollierungen der Änderungen,
Wiederherstellung von alten Ständen,
Archivierung der einzelnen Stände,
Koordinierung des gemeinsamen Zugriffs,
Gleichzeitige Entwicklung (Branch) und
Abspaltung (Fork).
Besonders beliebt ist heute die von Linus Torvalds
entwicklete verteilte Versionsverwaltung
(Englisch: Distributed Version Control, DVCS)
git
('global information tracker'; Website;
Anfang April 2005 gestartet und bereits
ab Linux 2.6.12-rc3 vom 20.04.2005
in Verwendung; aktuell: 2.42.0 vom 21.08.2023).
Einstimmung in Programmiersprachen
Historische Entwicklung
der drei Generationen
Eine Programmiersprache
wird verwendet, um über verständlichere Tokens und
eine logische Struktur einen Algorithmus
bzw. Datenstrukturen zu implementieren,
die der Rechner entsprechend verarbeiten kann,
nachdem ein Compiler und Linker
den Quelltext in ein Binärprogramm in Maschinensprache
umwandelt, die der Computer ausführen kann
(Interpreter
können alternativ statt eines Compiler verwendet werden,
sind aber langsamer, da die Erzeugung
des Maschinencodes zur Laufzeit erfolgt).
Die ersten Programme wurden direkt in Maschinensprache
über Schalter und später Lochkarten
dem Computer eingegeben:
1GL (1st Generation Language).
Danach wurde Assembler verwendet,
um besser zu merkende Mnemonics
statt einer Kette von 0|1‑en
eingeben zu können:
2GL (2nd Generation Language),
wobei aber immer noch das Vorgehen des Computers
direkt vorgegeben wird.
Erst danach wurden höhere Programmiersprachen, allen voran
C,
Fortran
und Cobol,
als erste Programmiersprachen der dritten Generation
eingeführt:
3GL (3rd Generation Language).
Es gibt keine 4GL, außer im Marketing!
C als hardwarenahe Programmiersprache
Wegen der Nähe zu C++, um das es
in den folgenden Abschnitten gehen wird,
und seiner Bedeutung im 🐧GNU/Linux‑Umfeld
soll hier zunächst kurz
auf C näher eingegangen werden.
Die Programmiersprache C wurde 1969‑1973
von Dennis A. Ritchie
(09.09.1941‑12.10.2011; er alleine ist
für das C‑Design verantwortlich)
in den Bell Laboratories
(AT&T‑Forschungsabteilung)
für die Programmierung des damals
neuen Unix‑Betriebssystems entwickelt,
wobei C aus der zuvor von Ken L. Thompson
(*04.02.1043) und Dennis Ritchie 1969/70
geschriebenen Programmiersprache B entwickelt wurde.
Für C ist noch Brian W. Kernighan
(*01.01.1942) zu nennen, der als Co‑Autor
des prominenten C‑Buchs und damit
ersten C‑Standards bekannt ist.
Hier die Historie
mit ausgewiesenen Normen dieser Programmiersprache:
| 1978 | Buch The C Programming Language: K&R C |
| 1989 | C Norm ANSI X3.159‑1989:
ANSI C / C89 |
| 1990 | C Norm ISO/IEC 9899:1990:
C90 (=C89; mit GCC über
-ansi, -std=c90 oder
-std=iso9899:1990) |
| 1995 | Minimale Erweiterung als C Norm
ISO/IEC 9899/AMD1:1995: C95 (mit GCC über
-std=iso9899:199409) |
| 1999 | C Norm {u.a. mit Ergänzungen
von C++} ISO/IEC 9899:1999: C99
{formerly C9X} (mit GCC über
-std=c99 oder -std=iso9899:1999) |
| 2011 | ISO‑Standard {u.a. bessere
Kompatibilität mit C++} ISO/IEC 9899/2011:
C11 {anfänglich C1X} (mit GCC über
-std=c11 oder -std=iso9899:2011) |
| 2018 | Minimale Erweiterung als C Norm
ISO/IEC 9899/2018: C18 bzw. C17 |
| 2023 | ?? Erweiterung als C Norm ISO/IEC 9899/2022:
{anfänglich C2x} C23 (mit GCC 14 über
-std=c23, -Wc11-c23-compat bzw.
-std=gnu23 – entsprechend verwendet
LLVM Clang 18 -std=c23) |
C wird auch dazu verwendet, von einer anderen
Programmiersprache in C umgesetzten Code mit den auf quasi
allen Plattformen existierenden C‑Compilern
mit ausgeklügelten Optimierungen zu übersetzen,
z.B. Chicken (Scheme),
EiffelStudio (Eiffel), Esterel,
CPython/PyPy,
Sather,
Squeak (Dialekt
von Smalltalk) und Vala.
Anders als C++ verfügt C
nicht über eine Standardbibliothek,
dennoch gibt es einige übliche Bibliotheken.
Unter Linux ist die wichtigste die GNU C Library
(glibc oder libc;
aktuell ist
glibc 2.43 vom 23.01.2026,
davor glibc 2.42 vom 28.07.2025,
zuvor glibc 2.41 vom 30.01.2025,
davor glibc 2.40 vom 22.07.2024,
zuvor glibc 2.39 vom 31.01.2024
(LWN mit Link zur Original‑Ankündigung;
vgl. auch Phoronix‑Artikel), davor glibc 2.38 vom 31.07.2023
(LWN mit Original‑Ankündigung),
siehe auch vorige Version glibc 2.37 vom 01.02.2023,
davor glibc 2.36 vom 02.08.2022
(LWN mit Original‑Ankündigung),
siehe auch deren vorige Version glibc 2.35 vom 03.02.2022
(LWN mit Original‑Ankündigung; vgl. auch Phoronix‑Artikel),
siehe auch vorige Version
glibc 2.34 vom 02.08.2021,
vgl. auch LWN mit
Original‑Ankündigung oder Phoronix‑Artikel,
bzw. noch ältere Versionen wie glibc 2.33 vom 01.02.2021,
vgl. auch LWN with
original announcement, bzw. glibc 2.32 vom 05.08.2020
[für gutes Zusammenspiel
wird GCC 10 empfohlen], vgl. Originalhomepage
und die Online Quellen
weiter unten).
Der Default in GCC
war anfangs -std=gnu90
(so wird es angegeben –
entsprechend lassen sich die anderen C‑Standards
mit GNU‑Erweiterungen auswählen wie z.B.
-std=gnu99 und -std=gnu11),
d.h. generell inkl. GNU‑Erweiterungen,
die in seltenen Fällen mit dem C‑Standard
in Konflikt treten können –
ab GCC 5.1 war der Default C11,
ab GCC 8.1 war es C18,
ab GCC 15.1 Anfang 2025 soll der Default
nun auf C23 angehoben werden
(d.h. den Dialekt GNU23; siehe Phoronix‑Artikel, 16.10.2024).
Zum Ausschalten der möglicherweise
in Konflikt tretenden GNU‑Erweiterungen
dienen die bereits in obiger Tabelle
angegebenen Parameter:
-ansi, -std=c90 oder -std=iso9899:1990;
-std=iso9899:199409;
-std=c99 oder -std=iso9899:1999 sowie
-std=c11 oder -std=iso9899:2011 –
zudem bewirkt der zusätzliche Parameter
-pedantic die für Verletzungserkennung
der Einschränkungen und der Syntax‑Regeln
benötigte Diagnostik auszugeben,
wohingegen -pedantic-errors GCC veranlasst,
Sprachverstöße als 'fatal error'
zu behandeln.
[Als Nebenbemerkung zur Verwendung
von GCC‑Version und C‑Standard in Linux:
Für den Kernel Linux wurde die minimale
GCC‑Version am 08.07.2020 für Linux 5.8-rc5
von 4.8 auf GCC 4.9 (erschienen in 2014) angehoben
(siehe Phoronix‑Artikel, 08.07.2020),
da es zu viele Workarounds
bzgl. pre‑4.9 GCC‑Fehlern gegeben hat.
GCC 4.8 wird z.B. noch
in RHEL 7 verwendet.
Mit Linux 5.15-rc1 wurde am 14.09.2021 sogar
GCC 5.1 von 2015 als neues allgemeinses Minimum
festgelegt, das zuvor
bereits für AArch64 galt
(vgl. Phoronix‑Artikel, 14.09.2021).
Aber neben GCC galt kein neuer C‑Standard:
er blieb auf C89.
Nach witziger Anspielung von Linus Torvalds,
auf C99 zu gehen, stellte sich dabei heraus,
dass man problemlos auf C11 gehen kann.
Ein Patch für neuen Default von -std=gnu11
wurde eingereicht und erfolgte
mit Linux 5.18
(siehe Phoronix‑Artikel,
28.02.2022).]
[Info:
Hare ist eine
neue System‑Programmiersprache ähnlich C,
die aber nicht automatisch libc einbindet
und als einfach, stabil und robust designt wurde,
auf statische Typen, manuelle Speicherverwaltung sowie
eine minimale Laufzeit setzt und am 25. April 2022
von Drew DeVault nach 2,5 Jahren Entwicklung
als vernünftig (aber nicht vollständig)
komplette Programmiersprache angekündigt wurde.
Die LWN‑Diskussion in Kommentaren
zeigt auch, dass viele mehr ein Ideal suchen
und zum heiligen Krieg aufrufen
und Wahl einer bestimmten Programmiersprache
als gutes Programmieren sehen,
weniger den steten Lernprozess der Programmierer,
Reviewer und Tool‑Programmierer;
Rust ist nicht per se sicherer,
und wie viele und welche Fehler
häufiger gemacht werden,
hängt von Programmierern ab.
Die Programmiersprache muss die Basis bereitstellen,
was Anfängerprogrammiersprachen wie Basic und Java
nicht hinreichend können.
Und bislang auch Rust noch nicht bewiesen hat.
Da es in der Diskussion erwähnt wurde,
möchte ich hier auch auf Zig hinweisen,
aktuell:
16.0 vom 13.04.2026 (siehe LWN‑Artikel),
eine ambitionierte Sprache,
die C als System‑Sprache ersetzen soll:
'C – but with the problems fixed'
(vgl. Wikipedia‑Artikel).
Man sollte sich den ![[YouTube-Icon]](images/youtube_inside.gif) Vortrag des Zig‑Autors anschauen,
mit einer Prise Humor!
Vortrag des Zig‑Autors anschauen,
mit einer Prise Humor!
Ich erwähne beide als Beispiele
neuer Kandidaten –
aber nicht ohne Ermahnen,
wie viele Sprachen es gibt –
und wie wenige
wirklich eine Rolle spielen.]
Empfehlung einer Programmiersprache
Wie bekannt sein dürfte, ist 🐧Linux von Linus Torvalds
mit erster Version 0.01 vom 17.09.1991
entwickelt worden,
später mit Version 0.12 im Januar 1992
unter GPL2‑Lizenz gestellt worden und
mit sehr wenigen Ausnahmen
(wie Assembler‑Code) vollständig
in C geschrieben
(ebenso die Desktops Gnome und XFCE oder das Bildverarbeitungsprogramm GIMP).
Für die Kernel‑Programmierung und andere
extrem effiziente Programme sieht er keinen Sinn
in C++, wie er mehrfach ausführte.
Die Empfehlung einer Programmiersprache
nach meiner persönlichen Meinung als bekennender
Unix‑Spezialist, der immer noch mit der Wissenschaft
verbunden ist,
wäre C, C++,
Fortran – und ggf. noch Python 3🥈.
Es gibt über 2500 Programmiersprachen
(einen ersten Eindruck der schieren Fülle
liefert bereits die Zeittafel
der Programmiersprachen
auf Wikipedia, obwohl hier nur ca. 7%
enthalten sind),
und man wird sich nur in einer richtig auskennen,
so wie man nur eine Hauptsprache
(zumeist die Muttersprache) hat.
Man sollte also gut nachdenken –
und nicht auf Java, C# oder unsinnige Zwänge
wie objektorientiertes Programmieren oder agile Softwareentwicklung
als ständige Verpflichtung hereinfallen.
Leider werden Schüler häufig genau mit solchen
schädlichen da oberflächlichen Dingen zuerst beworfen,
so dass ihr Weg deutlich erschwert wird.
Zumindest sollte jeder sich frühzeitig überlegen,
was vorrangig die Programmiersprache
der Wahl ist –
und dies hängt weniger vom Einsatzzweck ab:
Man kann von schönem Code sprechen,
wenn der Code den Eindruck vermittelt,
als ob die Programmiersprache
extra für das Problem gemacht wurde.
(nach Ward Canningham)
Ein guter Programmierer macht aus einer effizienten
und vollständigen Programmiersprache schönen Code.
Es ist Irrglaube, jedes Problem brauche
seine eigene Programmiersprache.
C und C++ haben dies bewiesen,
deren Schwerpunkt bei Effizienz und
Portierbarkeit liegt.
Und Programmierer haben die Verantwortung,
dass der Code einfach aussieht
(vgl. Clean Code,
R.C. Martin, S. 11f;
siehe Literaturliste).
Daneben gibt es große SW‑Projekte,
die in mehreren Sprachen (typisch 2-4)
vollzogen werden😵.
[Für einen Teil‑Überblick über moderne
Programmiersprachen sei hier auf Magazin iX Special –
Moderne Programmiersprachen 2020,
08.06.2020 hingewiesen.]
🥈 )
Neben C, C++ und Fortran
(1957; jüngste Norm
ist Fortran 2018;
von GCC unterstützt)
verblassen die anderen –
alle guten Dinge sind eben drei ;).
Nur mit Widerwillen habe ich
Python 3 angegeben
(Python wurde 1991‑94 entwickelt,
die jüngste Hauptversion 3,
ab 03.12.2008 verfügbar,
ist inkompatibel zu den beiden Vorgängern,
wobei Python 2 Ende 2019 mit EoL abtrat;
aktuell
ist Python 3.14.2 vom 05.12.2025;
vgl. Heise‑Artikel zu Python 3.13),
weil es im schulischen Bereich
die einzig halbwegs hochwertige Programmiersprache ist,
die vermittelt wird,
u.a. im Zusammenhang mit den Raspberry Pis.
Aber dies muss nicht sein, wie z.B. der Artikel Raspberry Pi Pico und C/C++ –
eine gute Kombination
(Heise‑Online, 19.03.2021) zeigt.
Auch wenn es eine Zufallskoinzidenz ist,
so sei dennoch erwähnt,
dass die 3D‑Grafiksuite Blender, die auch für 🕹️Spiele
eingesetzt wird, in C, C++ und Python
geschrieben wurde
(vgl. auch Projekte in
mehreren Programmiersprachen
in nachfolgender Fußnote).
Auch wenn Rust
interessant wirkt
(2010‑2015 Entwicklung durch Mozilla
zur ersten stabilen Version),
würde ich diese von Mozilla entwickelte Sprache
nicht direkt empfehlen, auch wenn es manche bereits jetzt
ganz anders sehen: es muss sich erst noch zeigen,
ob Rust die Zukunft
der Systemprogrammierung werden wird
wie im Beitrag vom 27.08.2019 behauptet
(siehe auch LWN‑Kommentare).
Allerdings scheint mir das ähnlich gehypte Go
(2009‑2012 Entwicklung
durch Google zur ersten stabilen Version;
von GCC unterstützt;
mit aktueller Version Go 1.26.1 vom 06.03.2026,
siehe Release Notes bzw. LWN-Artikel;
und Vorversion 1.21 vom 08.08.2023,
siehe Phoronix‑Artikel bzw. den vom 21.06.2023 zum RC;
und Vorgängerversion 1.20, siehe Phoronix‑Artikel, 01.02.2023;
bzw. Vorversion 1.19, siehe LWN‑Artikel, 02.08.2022, bzw. deren
Vorversion 1.18, siehe Phoronix‑Artikel, 15.03.2022;
bzw. aktueller Dokumentation)
eher ein Spielzeug zu sein,
das allenfalls gegenüber Java oder C#
überlegen ist.
Genau so unsinnig empfinde ich die neue
Google‑Schöpfung Carbon
(siehe Heise‑iX, 22.07.2022, Phoronix‑Artikel, 20.07.2022, bzw. 'Comparison between Carbon and Odin', 20.07.2022),
da hier mit 'einfach' und 'Brechen der ABI'
geworben wird, und dennoch ein Nachfolger von C++
angedacht wurde, man aber einen Syntax‑Mischmasch
aus vielen Sprachen erstellte ...
wenn man nun noch betrachtet, dass nur LLVM
aktuell anvisiert wird, sehen die Erfolgsaussichten
eher finster aus – zumal C++ eine
sich entwickelnde Programmiersprache ist.
Man kann auch Ranglisten
von Programmiersprachen finden,
wobei ich hier einige
aus diesem Jahr (ehemals 2019 –
soweit möglich aber aktuell gehalten)
erwähnen möchte –
auch wenn ich gleichfalls vorausschicken sollte,
dass man diesen Rängen
keine hohe Bedeutung zuweisen sollte:
- Mit besonderem Renommee
startet diese Aufzählung mit der IEEE Rangliste der Programmiersprachen
von von 2022,
bei der C auf Platz 2 und C++ auf Rang 3
landen, Platz 1 Phython,
nach C++ liegt Java auf Platz 5,
gefolgt von SQL, danach JavaScript auf Platz 7 und
R auf 9, gefolgt von HTML auf Rang 10;
Go liegt auf Platz 11,
Rust auf Rang 20 –
bei Job‑Ranking liegt aber
SQL auf dem 1. Platz;
zum Vergleich hier die Liste von 2019: IEEE Rangliste der Programmiersprachen,
bei der C auf Platz 3 und C++ auf Rang 4
landen, Platz 1 Phython, Platz 2 Java,
nach C++ liegt R auf Rang 5 und
JavaScript auf Rang 6;
die aktuelle IEEE Rangliste
wies 2021 lediglich ab Platz 5 Änderungen auf:
Javascript (#5) vor
C# (#6) vor R (#7) vor
Go (#8)
- Nach den Analysten RedMonk (07/2019)
liegt C++ auf Rang 5 und C auf Rang 9,
wobei die hier gezeigte Grafik von Beliebtheit
auf GitHub gegen Beliebtheit des Entwicklerforums
Stack Overflow interessant ist;
RedMonk (08/2021) zeigt C
auf dem 10. Platz.
- In einer Stack-Overflow-Umfrage unter Profientwicklern
wurden 2019 Rust und Python
zu den beliebtesten Sprachen
gezählt, C++ stand auf Rang 19,
C auf Rang 24.
- Nach einer anderen Umfrage von 2019 ist Python die populärste Programmiersprache
für Data Science.
- Monatlich gibt es auch die TIOBE Rangliste, die im September 2019
C auf Rang 2 hinter Java und C++ auf Rang 4
hinter Python ausweist für 02/2022 haben bzgl.
der ersten vier Plätze lediglich Python
und Java die Plätze getauscht.
Bei der Menge an Programmiersprachen,
den vielen Einsatzmöglichkeiten und
den unterschiedlichen Qualitätsstandards sollte man
diese Ranglisten nicht überbewerten.
Allerding sind C und C++ wohl die beiden Sprachen,
die jeder Kenner zu den Wichtigsten zählt,
Rust ist das New Kid
on the Block –
Python löst auch kritische Stimmen aus,
ist aber vielfach anwendbar.
Java ist durch die Smartphones
nicht zu verdrängen,
hatte aber nicht einmal bei der Entwicklerfirma Sun
jemals einen guten Ruf.
Und die Qualität der Erzeugnisse
(die in erster Linie vom Quellcode
des Programms und der verwendeten Bibliotheken abhängt,
aber ebenfalls vom Compiler, Linker, deren Flags beim Compilieren
und schließlich auch vom Betriebssystem
abhängt)
hat bei mir eine Umdefinition
von Begriffen ausgelöst:
eine App ist nichts Schickes oder Modernes,
sondern etwas, das wenig kann und nur so benutzt
werden kann,
wie der Programmierer dies erdacht hat –
also das Gegenteil von professionell.
Ein Programm ist qualitativ hochwertig,
lässt sich vielseitig einsetzen und konfigurieren,
dennoch effizient –
also ein Qualitätsprodukt für unterschiedliche
professionelle Workflows.
Eine Suite ist ein großes Programm,
das eigentlich viele einzelne enthält
(positive Beispiele wären
LibreOffice
[Schreibprogramm, Tabellenkalkulation, Präsentationsprogramm,
Zeichenprogramm, Datenbank etc.] oder SeaMonkey / Mozilla Suite
[WebBrowser, E‑Mail‑Programm,
Kalender etc.]);
eine App Suite ist somit eher
eine Müllhalde ...
Meine Kriterien sollten klar sein:
keine zu junge Programmiersprache,
keine, die auf den Gnadenschuss wartet,
sondern eine, die viele Programmier‑Techniken
möglich macht und damit zur Demonstration eingesetzt
werden kann und dadurch
zu vernetztem Wissen führt.
Somit nur so viel Black‑Box, wie nötig.
C und C++ stehen beide im Ruf,
schwer zu sein –
dies muss aber nicht sein.
Zumal man mit beiden nicht plötzlich
feststellen muss,
dass man ein Projekt nur mit einer anderen Sprache
sinnvoll beenden kann.
Die hervorragenden Programme in diesen Sprachen,
die besonders optimierenden Compiler,
die gewachsenen Bibliotheken, ...
all dies spricht für sich –
besser als jede Rangliste.
Ich fand es damals erstaunlich, dass Kommilitonen, die Informatik studierten,
ihre Zeit mit Miranda,
einer toten Kunstsprache und geistigen Vorbild von Haskell,
verschwenden mussten.
Die aktuellen Lehrpläne in Rheinland-Pfalz sprechen von
`der eingeführten Programmiersprache' –
und schränken diese nur insofern ein, dass diese
objektorientiertes Programmieren zulassen
(hier scheidet C aus; Rust kennt
keine Vererbung, ab Fortran 2003 beherrscht auch
dies OOP),
damit sie auch in Sek. II verwendet werden kann.
ABER als einzig genannte Programmiersprache
(wenn auch nur in einem Aspekt)
wird WHILE genannt,
die zur theoretischen Informatik gehört.
In diesem Zusammenhang sind die hier
genannten sechs Programmiersprachen alle sinvoll:
C, C++, Fortran, Python, Rust und Go.
Ich rate dennoch zu einer der beiden ersten,
C oder C++,
als erste Programmiersprache,
und habe mich als Vorbereitung, einen Einstiegskurs
ins Programmieren zu halten,
für C++ entschieden.
😵 )
Der Aspekt, dass unter bestimmten Bedingungen eine Mischung
von Sprachen sinnvoll ist, wird im Artikel
Wie viele Programmiersprachen
sind zu viel? (Heise Developer, 03.12.2019)
beleuchtet.
So wie an entscheidender Stelle eines Kernels neben C
auch mit Assembler zu programmieren erhebliche Performance
bringen kann –
wenn auch zu Lasten der Portierbarkeit,
so dass der Assembleranteil minimal gehalten werden sollte
(vgl. auch Blender
in obiger Fußnote).
Aber eine Aussage, mit allen Programmiersprachen
ließe sich quasi alles machen (im theoretischen Sinne
gleichermaßen mächtig),
ist und bleibt Unsinn.
Java ist für viele Anwendungsfälle eine Sackgasse,
C und C++ haben bewiesen, dass sich alle möglichen
Programme damit sinnvoll schreiben lassen.
Hat jemand wenig Ahnung, wird Java bestimmte Probleme
verhindern, will jemand etwas wirklich beherrschen,
hat diese Person mit C/C++ alle Möglichkeiten.
Ich würde daher die Zeit nicht
auf eine Anfängersprache wie Basic oder Java
verschwenden, wenn ich mich wirklich für Programmierung
interessierte.
Weniger ist mehr, aber drei Sprachen zu mischen
kann für ein großes Projekt
lohnend sein –
aber diese Sprachen haben jeweils
ein klares Einsatzgebiet und werden nicht willkürlich
eingesetzt – sonst wird die Software
nie eine angemessene Qualität aufweisen.
Einstimmung in C++
Historie und Normen von C++
C++
wurde 1979 von Bjarne Stroustrup
(Interview 22.08.2014)
bei AT&T als Erweiterung der Programmiersprache C
entwickelt.
Es ermöglicht ähnlich wie C eine effiziente und
maschinennahe Programmierung, lässt aber auch
ein hohes Abstraktionsniveau zu.
Zudem ist Bjarne Stroustrup der Ansicht,
dass C++ klar genug sei,
um Basiskonzepte erfolgreich zu lehren sowie
umfassend genug sei, um fortgeschrittene Konzepte und
Techniken zu lehren.
Wie zuvor angedeutet wird C++ immer noch verändert
und erweitert.
Einblicke in den Standardisierungsprozess bietet der Artikel
Wie geht die Standardisierung
von C++? (Heise‑Online, 23.03.2021,
von Dr. Peter Gottschling).
Zur Historie der Standards
dient die folgende Tabelle:
| 1985 | Erste Version von C++ |
| 1989 | Version 2.0 von C++ |
| 1998 | C++ Norm ISO/IEC 14882:1998:
C++98
🎇Neu🎉:
Templates, STL mit Containern und Algorithmen, Strings, I/O‑Streams |
| 2003 | Nachbesserung der C++ Norm
ISO/IEC 14882:2003: C++03 |
| 2011 | Modern C++
ISO/IEC 14882:2011: C++11 [ab GCC 4.8.1
und Clang 3.3 unterstützt {aus Linux‑Magazin 12/2017};
vgl. Heise‑Artikel
zur fertigen C++11‑Spezifikation]
🎇Neu🎉:
Vereinheitlichte Initialisierung,
Move‑Semantik,
Typinferenz
mit auto (nun kein Speicherklassen‑Specifier mehr)
und decltype,
Einführung der Lambda‑Funktion (auch anonyme Funktion genannt),
constexpt,
Übernahmen aus C11: z.B. long long
(Ganzzahl mit mindestens 64 bit) oder
Zusicherungen zur Übersetzungszeit static_assert,
Multithreading und das Speichermodell,
Reguläre Ausdrücke,
Smart Pointer,
Hash‑Tabellen,
std::array |
| 2014 | 1. Erweiterung von C++11 ISO/IEC 14882:2014:
{anfänglich C++1y} C++14 [ab GCC 5.0
und Clang 3.4 unterstützt {aus Linux‑Magazin 12/2017},
ab GCC 6.1 Default; vgl. Heise‑Artikel zum fast fertigen C++14]
🎇Neu🎉:
Verallgemeinerte Lambda‑Funktion,
Verallgemeinerte constexpr‑Funktion,
Erleichterte Lesbarkeit durch '
in Zahlenliteralen: 22'324'573UL,
Einführung des Binärliterals: 0b0101'1110,
Typdefinition bei Nutzer‑definierten Literalen:
als String "123"s,
Imaginärteil complex imaginaer {6.9i}; oder
Zeitdauern mit h, min, s, ms,
us und ns
(das doppelt definierte s
macht keine Probleme, da das eine auf Strings
und das andere auf Zahlen operiert),
auto als Rückgabetyp von Funktionen,
rand() wird nicht mehr empfohlen,
neues Attribut deprecated,
Reader Writer Locks,
Ergänzung der Standard‑Bibliothek (z.B. std::make_unique) |
| 2017 | 2. Erweiterung von C++11 ISO/IEC 14882:2017:
{anfänglich C++1z} C++17 [ab GCC 7
und Clang 5 unterstützt {aus Linux‑Magazin 12/2017},
seit GCC 9 nicht mehr experimentell,
Default ab GCC 11 {siehe Phoronix, 27.06.2020 bzw. Phoronix, 25.04.2021};
vgl. Heise‑Artikel zum fertigen C++17]
🎇Neu🎉:
Zur besseren Compile‑Zeit tragen bei:
Fold Expressions sowie
constexpr if für bedingte Übersetzung,
if und switch mit Initialisieren
(ähnlich wie die Laufvariable
in for),
Structured Binding,
neuer Typ std::byte
zum byte‑weisen Zugriff auf den Speicher,
Entfernung von
auto_ptr (C++11 std::unique_ptr
ist Ersatz) und
Trigraphs (drei Zeichen, die Sonderzeichen
darstellen, falls diese über Tastatur nicht eingebbar
sind, z.B. ??= für #),
std::stringview,
Parallele Algorithmen der STL,
Dateisystem‑Bibliothek,
neue generische Container std::any,
std::optional, std::variant |
| 2020 | 3. Erweiterung von C++11 ISO/IEC 14882:2020:
{anfänglich C++2a} C++20 [C++20 Default ab GCC 16: Phoronix‑Artikel, 27.11.2025],
(vgl. Heise‑Artikel zum Abschluss bzw. Artikel‑Serie auf Heise Developer
von Rainer Grimm zu C++20, jeweils vom
28.10.2019 + 04.11. + 11.11. + 18.11. +
25.11. + 02.12. + 09.12. + 16.12. + 23.12.2019 +
12.01.2020 + 20.01. + 27.01. + 02.02. + 10.02. +
17.02. + 24.02. + 02.03. + 09.03. + 16.03. +
23.03. + 30.03. + 06.04. + 13.04. + 20.04. +
27.04. + 04.05. + 11.05. + 18.05. + 25.05. +
01.06. + 08.06. + 15.06. + 22.06. + 29.06. +
06.07. + 13.07. + 20.07. + 27.07. + 03.08. +
10.08. + 17.08. + 24.08. + 14.09. + 21.09. +
28.09. + 05.10. + 12.10. + 19.10. + 26.10. +
02.11. + 09.11. + 16.11. + 23.11. + 30.11. +
07.12. + 14.12. + 21.12.2020 + 11.01.2021 + 18.01. +
25.01. + 01.02. + 08.02. + 15.02. + 22.02. +
01.03. + 08.03. + 15.03. + 22.03. + 29.03. +
05.04. + 12.04.2021:
Die vier großen Neuerungen + Überblick zur Kernsprache + Überblick zur Bibliothek + Überblick zur Concurrency + Zwei Extreme und die Rettung
dank Concepts + Concepts – die Details + Concepts –
die Placeholder Syntax + Concepts – Syntactic Sugar + Concepts – was wir
nicht bekommen + Vordefinierte Concepts + Concepts definieren + Die Concepts Equal und Ordering definieren + Die Concepts SemiRegular und
Regular definieren + Concepts in C++20: Eine Evolution oder
eine Revolution? + Die Ranges‑Bibliothek + Funktionale Pattern mit der Ranges‑Bibliothek + Pythonisch mit der Ranges‑Bibliothek + Pythons range‑Funktion,
die zweite + Die map‑Funktion von Python + Coroutinen – ein erster Überblick + Mehr Details zu Coroutinen + Ein unendlicher Datenstrom mit Coroutinen + Thread-Synchronisation mit Coroutinen + Coroutinen mit cppcoro + Mächtige Coroutinen
mit cppcoro + Thread‑Pools
mit cppcoro + Die Vorteile von Modulen + Ein einfaches
math‑Modul + Module Interface Unit und
Module Implementation Unit + Module strukturieren + Weitere offene Fragen
zu Modulen + Der Drei‑Weg‑Vergleichsoperator <=> + Mehr Details zum Spaceship‑Operator + Optimierte Vergleiche mit dem
Spaceship Operator + Designated Initializers + Zwei neue Schlüsselwörter in C++20:
consteval und constinit + Die Lösung des Static Initialization
Order Fiasco mit C++20 + Verschiedene Template‑Verbesserungen
mit C++20 + Mächtigere Lambda‑Ausdrücke mit C++20 + Mehr Lambda‑Features
mit C++20 + Neue Attribute mit C++20 + volatile und andere
kleine Verbesserungen in C++20 + Geschützter Zugriff auf Sequenzen
von Objekten mit std::span + constexpr std::vector und
constexpr std::string in C++20 + Neue praktische Funktionen für Container
in C++20 + std::format in C++20 + std::format um benutzterdefinierte
Datentypen erweitern + Noch mehr praktische Werkzeuge
in C++20 + Kalender und Zeitzonen in C++20:
1. Tageszeit + 2. Kalendertag + 3. Umgang mit Kalendertagen + 4. Zeitzonen + Sicherer Vergleich von Ganzzahlen
in C++20 + Prüfen von C++‑Features
mit C++20 + Bit‑Manipulationen mit C++20 + Atomare Referenzen mit C++20 + Synchronisation mit atomaren Variablen in C++20 + Performanzvergleich von Bedingungsvariablen
und Atomics in C++20 + Semaphoren in C++20 + Latches in C++20 + Barrieren und atomare Smart Pointers
in C++20 + Kooperatives Unterbrechen eines Threads
in C++20 + Ein verbesserter Thread
mit C++20 + Synchronisierte Ausgabe‑Streams mit C++20 + C++20: Einfache Futures
mit Coroutinen implementieren + Lazy Futures mit Coroutinen
in C++20 + C++20: Mit Coroutinen einen Future
in einem eigenen Thread ausführen + Ein unendlicher Datenstrom dank Coroutinen
in C++20 + Ein generischer Datenstrom mit Coroutinen
in C++20 + Jobs starten mit Coroutinen
in C++20 + Coroutinen in C++20: Automatisches Fortsetzen
eines Jobs auf einem anderen Thread)
🎇Neu🎉:
Module (Alternative zu Headern;
Präprozessor wird unnötig),
Coroutinen (zur asynchronen Programmierung),
Range‑Bibliothek (um Algorithmen der STL
direkt auf Container anzuwenden,
die Bereichs‑Objekte erlauben Verknüpfungen
mit dem Pipe‑Operator und deren Definition
auf unendliche Datenströme),
Concepts (eine Erweiterung der Templates;
siehe C++20‑Konzepte: Neue Wege
mit Konzepten,
Heise Developer, 08/2021),
Contracts (Interfaces für Funktionen/Methoden:
Vorbedingungen, Nachbedingungen und Zusicherungen während
der Ausführung) {Contracts wurden
für den Entwurf genehmigt, danach aber wieder
gelöscht – was gut ist,
kommt wieder ;}
Am 15.02.2020 wurde in Prag abgestimmt,
C++20 als DIS (`Draft International Standard')
zur endgültigen Zustimmung und Publikation zu schicken
(vgl. reddit-Artikel).
Er kann nun als abgeschlossen betrachtet werden und
die Arbeit am nächsten Standard
kann beginnen.
Der Entwurf wurde am 05.09.2020 bestätigt
(siehe Phoronix, 06.09.2020).
Für einen Überblick über C++20 siehe Magazin iX Developer –
Modernes C++, 28.09.2020 (vgl. auch
Weniger stupide Schreibarbeit:
Code reduzieren mit C++20,
iX 03/2021). |
| 2023 | 4. Erweiterung von C++11 ISO/IEC 14882:2023:
{anfänglich C++2b} C++23
C++23 ist Stand Juli 2023 inhaltlich fertig und
steht zur endgültigen Abstimmung an (siehe Heise‑Artikel,
Rainer Grimm, 10.07.2023):
mit 'Deducing This' {ermöglicht,
den implizit übergebenen this‑Zeiger
in einer Mitgliedsfunktionsdefinition
ähnlich wie in Python explizit zu machen und
somit CRTP (Curiously Recurring Template Pattern)
oder das Overload Pattern deutlich zu vereinfachen}
erfolgt eine kleine, aber sehr effektive Erweiterung
der Kernsprache;
daneben wird die C++23‑Bibliothek
viele wichtige Ergänzungen erhalten:
so lässt sich die Standardbibliothek direkt
mit 'import std;' importieren,
die C++20‑Formatspezifikation lässt sich
direkt in std::print und std::println
anwenden, ferner erhalten wir aus Performancegründen
flache assoziative Container
wie std::flat_map – verwendbar anstelle
von std::map, die Schnittstelle std::optional
wird aus Gründen der Komposibilität
um eine monadische Schnittstelle erweitert,
der neue Datentyp std::expected hat bereits
eine komponierbare Schnittstelle und kann
einen erwarteten oder einen unerwarteten Wert
zur Fehlerbehandlung speichern, dank std::mdspan
erhalten wir einen mehrdimensionalen Span, und
schließlich ist std::generator die erste
konkrete Coroutine zur Erzeugung eines Zahlenstroms und
Teil der in C++23 signifikant erweiterten
ranges-Bibliothek; zudem (vgl. LWN‑Artikel)
werden hazard pointers und user‑space
read‑copy‑update (RCU) unterstützt.
Vorschläge können noch bis Januar 2025
eingereicht werden.
[??? erste Vorschläge umfassten:
`Modular Standard Library',
Bibliotheks-Unterstützung von `Coroutines', `Executors' und
`Networking', auf der Sprachseite Intensivierung von
`Reflection' inklusive `Introspection',
Programmierung zur Compile‑Zeit und Generierung sowie
`Pattern Matching' und `Contracts' ... ???]
|
| 2026 | 5. Erweiterung von C++11 ISO/IEC 14882:2026:
{anfänglich C++2c} C++26
...
[??? erste Spekulationen vgl. Heise‑Developer, 16.11.2023 oder auch von Herb Sutter: "Summer ISO C++
standards meeting",
02. Juli 2024]
|
Im heutigen Sprachgebrauch bedeutet Standard C++ immer C++98 / C++03,
Modern C++ bezeichnet C++11 und
dessen Erweiterungen C++14 / C++17 sowie
den nächsten großen Wurf C++20.
Was zwischen den beiden Kategorien anvisiert wurde:
es sollte die Erlernbarkeit der Sprache
für Anfänger verbessert werden,
ebenso waren Verbesserungen im Hinblick
auf die Systemprogrammierung sowie zur Erstellung
von Programmbibliotheken vorrangig.
Manche gehen so weit zu behaupten, in C++20 änderte sich
so viel, dass es eher mit C++98 oder C++11
als mit den kleineren Erweiterungen
C++14 und C++17 (auch C++23 ist wohl
in der Tradition von C++17)
verglichen werden kann
(vgl. Heise‑Online‑Interview vom Sommer 2020:
Bjarne Stroustrup: Jeder C++‑Standard ist
eine Momentaufnahme –
Welche neuen Features von C++20
sind für Entwickler langfristig bedeutend und
wo geht die Reise hin ...,
15.01.2021 online gestellt;
Modernes C++ bzgl. Templates erörtert Rainer Grimm als Fortsetzung der Neuerungen
zu C++20 – siehe oben bei C++20 – in Artikeln auf Heise Developer, jeweils vom
26.04.2021 + 03.05. + 10.05. + 17.05. + 24.05. +
31.05. + 07.06. + 14.06. + 21.06. + 28.06. +
05.07. + 12.07. + 19.07. + 26.07. + 02.08. +
09.08. + 16.08. + 06.09. + 13.09. + 20.09. +
27.09. + 04.10. + 11.10. + 18.10. + 25.10. +
01.11. + 08.11. + 15.11. + 22.11. + 29.11. +
06.12. + 13.12. + 20.12.2021 + 10.01.2022 + 17.01. +
24.01. + 31.01. + 07.02. + 14.02. + 21.02. +
28.02. + 07.03. + 14.03. + 21.03. + 28.03. +
04.04. + 11.04. + 19.04. + 25.04. + 02.05. +
10.05. + 16.05. + 23.05. + 30.05. + 07.06. +
13.06. + 20.06. + 29.06. + 04.07. + 11.07. +
01.08. + 08.08. + 16.08. + 22.08. + 30.08. +
05.09. + 12.09. + 19.09. + 26.09. + 04.10. +
10.10. + 17.10. + 24.10. + 31.10. + 07.11. +
14.11. + 21.11. + 28.11. + 05.12. + 12.12. +
19.12.2022 + 09.01.2023 + 16.01. + 23.01. + 30.01. +
06.02. + 13.02. + 20.02. + 27.02. + 06.03. +
13.03. + 20.03. + 27.03. + 03.04. + 11.04. +
17.04. + 24.04. + 02.05. + 08.05. + 15.05. +
23.05. + 30.05. + 19.06. + 26.06. + 03.07. +
10.07. + 17.07. + 25.07. + 31.07. + 07.08. +
14.08. + 22.08. + 28.08. + 04.09. + 11.09. +
18.09. + 25.09. + 02.10. + 09.10. + 16.10. +
23.10. + 30.10. + 06.11. + 13.11. + 20.11. +
27.11. + 04.12. + 11.12. + 18.12.2023 + 08.01.2024 +
15.01. + 22.01. + 29.01. + 05.02. + 12.02. +
26.02. + 04.03. + 18.03. + 25.03. + 08.04. +
15.04. + 22.04. + 06.05. + 16.05. + 22.05. +
18.06. + 24.06. + 01.07. + 15.07. + 05.08. +
13.08. + 20.08. + 27.08. + 03.09. + 10.09. +
16.09. + 23.09. + 01.10. + 08.10. + 14.10. +
21.10. + 28.10. + 04.11. + 18.11. + 25.11. +
04.12. + 09.12. + 16.12. + 23.12.2024 +
13.01.2025 + 20.01. + 27.01. + 03.02. + 10.02. +
17.02. + 24.02. + 10.03. + 24.03. + 07.04. +
05.05. + 19.05. + 02.06. + 17.06. + 30.06. +
14.07. + 28.07. + 11.08. + 25.08. + 08.09. +
22.09.2025 +13.10.2025+03.03.2026 ...:
Der Gewinner ist: Templates +
Templates: Erste Schritte +
Funktions‑Templates +
Funktions‑Templates: Mehr Details
zu expliziten Template‑Argumenten
und Concepts +
Klassen‑Templates +
Vererbung und Memberfunktionen von
Klassen‑Templates +
Alias Templates und
Template Parameter +
Template Arguments +
Die automatisch Bestimmung
der Template Argumente
von Klassen‑Templates +
Einführung in
die Template Spezialisierung +
Template‑Spezialisierung: Mehr Details
zu Klassen‑Templates +
Vollständige Spezialisierung
von Funktions‑Templates +
Parallele Algorithmen der STL
mit dem GCC‑Compiler +
Performance der
parallelen STL‑Algorithmen +
Template‑Instanziierung +
Variadic Templates oder die Power
der drei Punkte +
Mehr über
Variadic Templates ... +
C++20‑Module: Private Module Fragment und
Header Units +
Von Variadic Templates
zu Fold Expressions + Clevere Tricks mit Parameterpacks und
Fold Expressions + Eine std::variant mit dem
Overload Pattern besuchen + Die speziellen Freundschaften
von Templates + Abhängige Namen + Automatischer Rückgabetyp (C++98) + Automatischer Rückgabetyp (C++11/14/20) + Template‑Metaprogrammierung:
Wie alles begann + Template Metaprogrammierung:
Wie es funktioniert + Template Metaprogrammierung:
Hybride Programmierung + Die Type‑Traits Bibliothek:
Typprüfungen + Die Type‑Traits Bibliothek:
Typvergleiche + Die Type‑Traits Bibliothek:
std::is_base_of + Die Type‑Traits Bibliothek:
Korrektheit + Die Type‑Traits Bibliothek:
Optimierung + Dining Philiosophers Problem I + Dining Philiosophers Problem II + Dining Philiosophers Problem III + constexpr Funktionen + constexpr und consteval Funktionen
in C++20 + constexpr if + Statische und
dynamische Polymorphie + Mehr Details zur statischen und
dynamischen Polymorphie + Mixins + Temporäre Objekte vermeiden
mit Expression Templates + Softwaredesign mit Policies + Softwaredesign mit Traits und
Tag Dispatching + Eine std::advance Implementierung
mit C++98, C++17 und C++20 + Type Erasure auf der Basis
von Templates + Definition von Concepts + Concepts mit Requires Expressions +
Requires Expressions in C++20
direkt verwenden + Datentypen mit Concept prüfen –
Die Motivation + Datentypen mit Concept prüfen + Die Ranges Bibliothek in C++20:
Mehr Details + Projektionen mit Ranges + Sentinels und Concepts
mit Ranges + Verbesserte Iteratoren mit Ranges +
Ranges: Verbesserungen mit C++23 +
Ein erster Überblick:
Design Patterns und
Architekturmuster mit C++ +
Softwareentwicklung: Patterns bringen
klare Vorteile +
Die Geschichte der Patterns
in der Softwareentwicklung +
Klassifizierung von Design Patterns
in der Softwareentwicklung +
Klassifikation von Mustern
in der Softwareentwicklung +
Die Struktur von Patterns
in der Softwareentwicklung +
Patterns in der Softwareentwicklung:
nicht isoliert, sondern in Beziehung +
Softwareentwicklung: Antipatterns –
die böse Schwester der Design‑Patterns + Softwareentwicklung:
Das Design‑Pattern – Fabrikmethode zum Erzeugen
von Objekten + Softwareentwicklung: Design‑Pattern Fabrikmethode
ohne Probleme + Patterns in der Softwareentwicklung:
Das Singleton‑Muster + Patterns in der Softwareentwicklung:
Vor‑ und Nachteile
des Singleton‑Musters + Patterns in der Softwareentwicklung:
Die Alternativen zum Singleton‑Muster +
Patterns in der Softwareentwicklung:
Das Adapter‑Muster + Patterns in der Softwareentwicklung:
Das Brückenmuster + Patterns in der Softwareentwicklung:
Das Decorator‑Muster + Patterns in der Softwareentwicklung:
Das Kompositum‑Muster + Patterns in der Softwareentwicklung:
Das Strukturpattern Fassade + Patterns in der Softwareentwicklung:
Das Stellvertretermuster + Patterns in der Softwareentwicklung:
Das Beobachtermuster + Patterns in der Softwareentwicklung:
Das Besuchermuster + Patterns in der Softwareentwicklung:
Die Template‑Methode + Patterns in der Softwareentwicklung:
Das Strategiemuster + Idiome in der Softwareentwicklung:
Das Copy‑and‑Swap‑Idiom + Techniken in der Softwareentwicklung:
Partial Function Application + Softwareentwicklung: Argument‑Dependent Lookup und
Hidden‑Friend‑Idiom in C++ + Programmiersprache C++: Rule of Zero,
or Six + Idiome in der Softwareentwicklung:
Reguläre Datentypen + Idiome in der Softwareentwicklung:
Value‑Objekte + Patterns in der Softwareentwicklung:
Das Nullobjekt‑Entwurfsmuster + Idiome in der Softwareentwicklung:
Das Iterator‑Protokoll + Idiome in der Softwareentwicklung:
Covariant Return Type + Idiome in der Softwareentwicklung:
Polymorphie und Templates + Woran erkennt man
eine gute Softwarearchitektur? + Strukturen in der Softwareentwicklung:
Architekturmuster + Patterns in der Softwarearchitektur:
Das Schichtenmuster + Patterns in der Softwarearchitektur:
Das Pipes‑and‑Filters‑Muster + Patterns in der Softwarearchitektur:
Das Broker‑Muster + Patterns in der Softwarearchitektur:
Model‑View‑Controller + Patterns in der Softwarearchitektur:
Das Reactor‑Muster + Softwarearchitektur: Patterns für
nebenläufige Anwendungen + Patterns in der Softwareentwicklung
für das Teilen von Daten
zwischen Threads + Softwareentwicklung:
Umgang mit Veränderung–
das Thread‑Safe‑Interface + Softwareentwicklung –
Umgang mit Veränderung: Locking + Softwareentwicklung:
Umgang mit Veränderung –
Guarded Suspension + Patterns in der Softwarearchitektur:
Das Active Object + Patterns in der Softwarearchitektur:
Monitor Object + Fehlerkorrektur zum Beitrag
über Monitor Object
in der Thread‑Safe Queue + C++23: Der neue C++‑Standard
ist fertig + C++23: Deducing This erstellt
explizite Zeiger + C++23: Syntactic Sugar
with Deducing This + C++23: Die kleinen Perlen
in der Kernsprache + C++23: Mehr kleine Perlen
in der Kernsprache + Programmiersprache C++: Benchmark der
parallelen STL‑Algorithmen + C++23: Eine modularisierte Standardbibliothek
und zwei neue Funktionen + C++23: Eine neue Art der Fehlerbehandlung
mit std::expected + C++23: Vier neue
assoziative Container + C++23: Eine multidimensionale View + C++23: Ranges Verbesserungen
und std::generator + Softwareentwicklung: Polymorphe Allokatoren
in C++17 + Softwareentwicklung: Spezielle Allokatoren
mit C++17 + Softwareentwicklung: Optimierung mit Allokatoren
in C++17 + C++20: Modulunterstützung
der großen drei Compiler + C++20: Weitere Details
zur Modulunterstützung der großen
drei Compiler + Die Ranges‑Bibliothek in C++20:
Designentscheidungen + Die Ranges‑Bibliothek in C++20:
Weitere Designentscheidungen + Softwareentwicklung: Ein kompakte Einführung
in Coroutinen von Dian‑Lun Li + Coroutinen: Ein Scheduler
für Tasks – Teil 2
von Dian‑Lun Li + Programmiesprache C++:
Ein Prioritäts‑Scheduler
für Coroutinen + Programmiersprache C++: Ein anspruchsvoller
Prioritäts‑Scheduler für Coroutinen + Korrektur: Bug in dem Priority‑Scheduler
für Coroutinen im C++‑Blog + Softwareentwicklung: Ein Coroutine‑basierter
Consumer‑Producer‑Workflow + Programmiersprache C++: Der automatisch
generierte Gleichheitsoperator + Softwareentwicklung: std::span in C++20:
Weitere Details + Softwareentwicklung: Die Formatierungsbibliothek
in C++20 + Die Formatierungsbibliothek in C++20:
Der Formatstring + Die Formatierungsbibliothek in C++20:
Details zum Formatstring + Die Formatierungsbibliothek in C++20:
Formatieren benutzerdefinierter Datentypen + Mehr Details zur Formatierung
benutzerdefinierter Datentypen in C++20 + Zeit in C++20: Einführung in
die Chrono‑Terminologie + Zeit in C++20:
Grundlegende Chrono‑Terminologie mit Zeitdauer
und Zeitpunkt + Zeit in C++20:
Neue Datentypen für die Tageszeit und
das Kalenderdatum + Zeit in C++20:
Kalendertermine erstellen + Zeit in C++20:
Kalendertermine darstellen und prüfen + C++20: Abfrage von
Kalenderdaten und Ordinaldaten + Zeit in C++20:
Details zu der Arbeit mit Zeitzonen + Zeitzonen in C++20:
Online‑Klassen + Zeit in C++20: Chrono I/O + C++20: Chrono I/O: Unformatiert und
formatiert + Zeit in C++:
Parser formatierter Eingaben + Softwareentwicklung: Kooperatives Unterbrechen
eines Threads in C++20 + C++20: Kooperative Unterbrechung eines Thread
mit Callbacks + C++20: Compiler‑Funktionen
mit Feature‑Testing‑Makros ermitteln +Programmiersprache C++23: Was sonst noch
Interessantes im Standard dabei ist + C++26 wird der nächste
große C++-Standard
(Überblick über die großen und
kleinen Schritte zu Modernem C++) + Ein Überblick über C++26:
die Kernsprache + Ein Überblick über C++26:
die Bibliothek + Ein Überblick über C++26:
die arithmetische Erweiterung
in der Bibliothek + Ein Überblick über C++26:
Zusätzliche Bibliotheksfunktionen
und Concurrency + Programmiersprache:
Reflection in C++26 + Reflexion in C++26:
Metafunktionen + Reflexion in C++26:
Metafunktionen für Enums und Klassen + Reflexion in C++26:
Layout der Datentypen bestimmen + Softwareentwicklung:
Contracts in C++26 + Softwareentwicklung: Platzhalter und
erweiterter Zeichensatz in C++26 + C++26 Core Language:
Kleine Verbesserungen + Programmiersprache C++: Concurrency mit
std::execution + Programmiersprache C++:
cstd::execution –
Asynchrone Algorithmen + Programmiersprache C++: Erweiterung für
'Inclusive Scan' in C++26 + Programmiersprache C++: Komposition von Sendern
mit std::execution + C++26: Die Sender‑Fabriken, Adapter und
Consumer von std::execution + Programmiersprache C++: Mehr Sender
für std::execution in C++26 + C++26‑Bibliothek: Verbesserte Verarbeitung
von Strings + Programmiersprache C++26: Vereinfachter Umgang
mit Pointer‑Adressen + Deferred Reclamation in C++26:
Read‑Copy Update und Hazard Pointers + C++26: Vereinfachte Implementierung
eines Lock‑freien Stacks + C++26: Vollständige Implementierung
eines Lock‑freien Stacks + C++26: Ein Lock‑freier Stack
mit Atomic Smart Pointer + C++26: Ein einfacher Garbage Collector
für den Lock‑freien Stack + C++26: Ein Lock‑freier Stack
mit Hazard‑Pointer‑Implementierung + Lock‑freier Stack in C++26:
Details zur Implementierung
von Hazard Pointers + Lock‑freier Stack:
Details zur Implementierung von Hazard Pointers,
Teil 2 + Programmiersprache C++: Hazard Pointers
in C++26 + C++: Vorschlag von Oliver Schädlich
zu "atomic<shared_ptr<>>" –
ein Experiment + Neuerungen in C++26:
Read‑Copy‑Update + Neuerungen in C++26:
Datenparallele Datentypen (SIMD) +
Datenparallele Typen in C++26:
ein Beispiel aus der Praxis +
Datenparallele Typen in C++26:
Bedingte Ausführung von Operationen +
Datenparallele Datentypen in C++26:
Reduktion eines SIMD-Vektors + Datenparallele Typen in C++26:
SIMD‑Algorithmen + Contracts in C++ 26:
Ein tiefer Einblick in die Verträge +
Contracts in C++26:
Evaluations‑Semantik +
Programmiersprache C++26: Sicherheitsverbesserungen
in der Kernsprache +
Modernes C++: Trauer um
unseren Blogautor
🪦Rainer Grimm!
C++ für eingebettete Systeme:
constexpr und consteval;
vgl. aktuelle C++‑Artikel auf Heise von Rainer Grimm etc.).
Auf jeden Fall sollte man
modernes C++ lernen –
Dokumente, die nicht zumindest auf dem Stand
von C++14 sind,
machen heutzutage (2021+)
keinen Sinn mehr –
sowohl von der Vollständigkeit als auch
vom Gedanken eines Abschlusses ist aktuell
C++17 ein attraktives Ziel für neue Projekte
wie auch zum Unterrichten.
Zu C++ (bzw. jeder Version
von C++) gehört auch die Standardbibliothek
(STL: Standard Template Library oder
libstdc++, als dessen Designer gilt Alexander Stepanow – Link zu
seiner Homepage
mit Veröffentlichungen von Alexander A. Stepanov;
vgl. Core Guidelines).
Zudem kann man auch Boost
verwenden (dafür GCC den Pfad mit -L-Option angeben).
Boost stellt eine freie Sammlung
von C++‑Quell‑Unterbibliotheken dar
(hier eine Liste
aller Boost‑Bibliotheken),
die durch Fachleute überprüft als Erweiterung
und Prüfstand zukünftiger Zusätze
von libstdc++ dienen (zukünftig ist
1.87 für den 11.12.2024 geplant, aktuell ist 1.86 vom 14.08.2024, davor 1.85 vom 15.04.2024, zuvor 1.84 vom 13.12.2023, davor 1.83 vom 11.08.2023, zuvor 1.82 vom 14.04.2023, davor 1.81 vom 14.12.2022, zuvor 1.80 vom 10.08.2022,
davor 1.79 vom 13.04.2022,
zuvor 1.78 vom 08.12.2021,
davor 1.77 vom 11.08.2021,
zuvor 1.76 vom 16.04.2021,
davor 1.75 vom 11.12.2020;
vgl. Heise‑Artikel zu Boost 1.77 vom 16.08.2021 bzw. zu Boost 1.68 vom 13.08.2018).
Siehe Online Quellen
bzgl. weiterer Infos zu beiden Bibliotheken.
[Zur Vollständigkeit sei auf eine weiter
Bibliotheks‑Sammlung hingewiesen,
ACE – The ADAPTIVE
Communication Environment: OO Network Programming Toolkit
in C++.]
In C++17 ist z.B. die Dateisystem-Bibliothek
auf neueren GCCs enthalten, so dass man dieses
wertvolle Werkzeug nicht mehr
über die umständlichere Einbindung
der Boost-Bibliotheken erhält – die Entwicklung
der Standard-Bibliotheken (libstdc++)
ist also ebenso wichtig
wie die des Basis‑Sprachumfangs (C++;
vgl. hierzu auch LLVM/Clang, das libc++ oder
GCC's libstdc++ nutzt).
Wie oben bereits
erwähnt unterstützt GCC viele
der C++‑Standards
(eine Übersicht, welcher Compiler welche Teile
der C++‑Versionen unterstützt, liefert cppreference):
Der Default seit GCC 11 ist C++17 mit Erweiterungen
(hier sollen zum ersten Mal
alle Programme konsistent in Modernem C++
programmierbar sein, da vieles von C++11 und C++14
nur optional war und erst mit C++17
obligatorisch wird) –
dies bleibt auch für GCC 12 so
(hier sind C++20‑ wie auch C++23‑Merkmale
immer noch experimentell, was sich frühestens
mit GCC 13 in 2023 ändern könnte),
für GCC 6.1 bis GCC 10
ist es C++14,
vor GCC 6.1 war der Default C++98.
[Als Nebenbemerkung zur Verwendung
von GCC‑Version und C++‑Standards
in großen Projekten: durch eine aktuelle Diskussion auf
der Linux Kernel Mailing List
(Bericht von Phoronix, 10.01.2024)
wird gerade eine Diskussion von 04/2018 neu entfacht,
ob man mit C++ nicht deutliche Vorteile
gegenüber C für die Kernelentwicklung von Linux
nutzen könnte, wobei der aktuelle Vorschlag
vom 09.01.2024 eine Untermenge
von C++14 / C++20 für eine zukünftige
Nutzung empfielt.
Linux ist ein riesiges und bedeutendes Projekt
und somit langsam bei extremen Änderungen –
so wurde C11 statt C89 erst 2022 realisiert
und auch Rust beschränkt auf Gerätetreiber
macht gute Fortschritte, ist aber noch nicht
wirklich angekommen.
Dies zeigt zumindest deutlich, dass C++
in der modernen Variante an Reife gewonnen hat
und sich für extrem unterschiedliche Dinge eignet.
Sogar GCC selbst ist seit Version 4.8
(03/2013) in C++ implementiert
(siehe Initiator Ian Lance Taylor, 06.05.2008,
LWN, 13.03.2013,
![[Wikipedia-en-Icon]](images/Wikipedia_logo_en.gif) GCC‑Historie
[englisch, die deutsche Fassung
ist oberflächlicher])]
GCC‑Historie
[englisch, die deutsche Fassung
ist oberflächlicher])]
Eigenschaften und
sich daraus ergebende Haupt‑Anwendungsbereiche
C++ wird sehr viel für Bedienoberflächen
(GUI; z.B. KDE; oder auch Schreibprogramme
wie LibreOffice oder
AbiWord)
verwendet, im Grafikbereich (insb. bei 🕹️Spielen,
z.B. SuperTux oder
SuperTuxKart,
wie auch bei der Spiel-Engine Godot [ab 4.0
soll C++11 verwendet werden; für einen
englischen Überblick siehe Godot & C++ – How, What and Why?
sowie Why Godot Over Unity or
Unreal Engine? bzw. die Godot News];
siehe Literatur zur
Spiele‑Programmierung sowie
🕹️Game‑Engines und
Frameworks),
ist aber auch für numerische Berechnungen
(auch wenn es dafür, anders als Fortran,
nicht geschaffen wurde),
Betriebssysteme
(auch wenn hierfür C und Assembler
geeigneter erscheinen)
oder Datenbankzugriffe im Einsatz.
Zudem wird auch für GCC immer mehr C++ eingesetzt,
seit Konvertierungsbemühungen 08/2012
zum damaligen GCC 4.8 für GCC selbst
verwendet – und aktuell berät man,
auf C++11 (d.h. Modern C++; und diese frühe Version
ermöglicht auch den Einsatz von GCC 5
bzw. 6; anvisiert wird der Einsatz
des C++ Speicher-Modells mit atomic classes, for each loops, besserer Multi-Threading
Unterstützung, etc.)
umzusteigen, wohingegen LLVM gerade
den Übergang zu C++14 vorbereitet (vgl. Phoronix-Artikel vom 30.09.2019).
Die Flexibilität kommt auch in Multiparadigmen
zum Ausdruck:
generisch, imperativ, objektorientiert, prozedural,
strukturiert, funktional.
Man braucht also keine Verpflichtung zu spüren,
einem bestimmten Programmierstil zu folgen,
auch wenn dies eigentlich nicht zur Aufgabe bzw.
zu dem Problem passt.
Man kann schnell Code schreiben,
zu einem guten C++‑Programmierer gehört
aber einiges (wer Automatismen braucht,
die Performance kosten aber narrensicher sein sollen,
sollte sich mit Java oder C# bescheiden –
aber warum das Niveau soweit senken ... 😳 ).
Meine Wahl fiel auf C++, weil ich mir
diese Sprache schon immer anschauen wollte,
diese häufig in anspruchsvollen 🕹️Spielen
(vgl. Liste
freier Computerspiele)
Verwendung findet und
eine gewisse Nähe zu C vorhanden ist.
Wenn ich irgendwann Schülern eine Sprache
näherbringen sollte,
darf ich mich
dafür nicht schämen müssen –
und dies würde ich tun,
wenn ich die bisher an Schulen vorgefundenen Wege
beschreiten würde.
Also: C++ auf GNU/Linux.
Vorstellen eines Beispiel‑Programms in C++
Quelltext
Als einfachstes C++-Programm (mit Beispielen
in vielen anderen Programmiersprachen)
sei auf das Hello World
C++‑Beispiel hingewiesen.
Nachfolgend soll es um ein etwas
komplexeres Beispielprogramm gehen:
/******************************************************************************
* C++-Programm 'example.cpp' im Verzeichnis '~/mycpp/jmb/' *
* *
* Funktion: "Zerlegung einer Zahl in ihre Primfaktoren" *
* *
* J.M.B. [URL: https://www.jmb-edu.de/cpp_programming.html#progcppexamp] *
* *
* Lizenz: (c) 2019 unter GPLv3: https://www.gnu.org/licenses/gpl-3.0.txt *
* *
* Erstellung: 05.08.2019 *
* *
* Letzte Umgestaltung: 07.09.2019 (Phase 2; vgl. Phase 1 vom 08.08.2019) *
******************************************************************************
*/
/* Einbau von Bibliotheken der C++-Standardbibliothek: */
# include <string> // fuer std::string {Container-Typ}:
// std::stoi/stoll, std::to_string
# include <vector> // fuer std::vector {Container-Typ}
# include <iostream> // fuer std::cin, std::cout, std::endl
# include <sstream> // fuer std::stringstream/ostringstream
# include <fstream> // fuer std::ofstream (Datei: file)
# include <stdexcept> // exception - zur Ausnahme-Behandlung
# include <cmath> // C-Mathe-Lib in C++ fuer: std::sqrt(l)
# include <ctime> // " std::time_t/struct tm/time/localtime
/* Gebrauch von ANSI-Farben in kompatiblen Terminals:
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* Effekt Code | Farbe Vordergrund Hintergrund | ASCII 27 = \033
* zuruecksetzen 0 | schwarz 30 40 | = ESC-Zeichen
* fett/hell 1 | rot 31 41 | Z.B. hell rot
* unterstrichen 4 | gruen 32 42 | auf schwarz
* invertiert 7 | gelb/orange 33 43 | "\033[4;31;40m"
* fett/hell aus 21 | blau 34 44 | Clear Screan:
* unterstri. aus 24 | magenta 35 45 |"\033[2J\033[1;1H"
* invertiert aus 27 | cyan 36 46 | Reset: "\033[0m"
* * Just play ! * | weiss/grau 37 47 | * Have fun! *
*/
// * Globale String-Konstanten zur Festlegung der ANSI-Steuercodes, hier
// * bzgl. STIL_VGFARBE_HGFARBE (siehe Erklaerung oben; Esc=x1B=27=\033):
const std::string // Definition aller ANSI-ESC-Sequenzen / Farben
// Anstelle: '# define RESET "\033[0m"' fuer Praeprozessor nun:
RESET = "\x1B[0m", // Reset to Defaul: zuruecksetzen
CLRSCR = "\x1B[2J\x1B[1;1H", // wie in C++ 'std::system("clear");'
UL_LWHITE_BROWN = "\x1B[1;4;37;43m",// unterstrichen weiss auf orange
LWHITE_BROWN = "\x1B[1;37;43m", // weiss auf braun/orange
UL_LYELLOW_BROWN = "\x1B[1;4;33;43m",// unterstrichen gelb auf braun/orange
LYELLOW_BROWN = "\x1B[1;33;43m", // gelb auf braun/orange
UL_LRED_BLACK = "\x1B[1;4;31;40m",// unterstrichen rosa auf schwarz
LRED_BLACK = "\x1B[1;31;40m", // rosa auf schwarz
LYELLOW_BLACK = "\x1B[1;33;40m", // gelb auf schwarz
UL_LYELLOW_GREEN = "\x1B[1;4;33;42m",// unterstrichen gelb auf gruen
RED_BROWN = "\x1B[31;43m"; // rot auf braun/orange
// * Globale Variable zur Festlegung, ob Ausgabe ohne ANSI-Farben gewuenscht ist
bool farbLos = false; // wird nur von main umgeaendert!
// * Nun eine zweiteilige Funktion zum (ggf. farbigen) Start bzw. Ende ;)
void begruessung (std::ostream& os, bool anfang, std::string prgname)
{ using std::endl; // endl bedeutet nun std::endl
if (anfang) // * anfang: 1 = true (= Begruessung)
{ /* Begruessung */
if (farbLos)
{ // prgname = argv[0], d.h. Aufrufstring
os << " * Programm '" << prgname << "' zur Ausgabe der Primfaktoren *";
os << endl;
} else
{ // prgname = argv[0], d.h. Aufrufstring
os << UL_LYELLOW_BROWN << " * Programm '" << UL_LYELLOW_GREEN << prgname;
os << UL_LYELLOW_BROWN << "' zur Ausgabe der Primfaktoren *" << RESET;
os << endl;
}
} else // * anfang: 0 = false (= Abschied)
{ /* Verabschiedung */
if (farbLos)
{
os << " * Macht's gut, Kinners! \U0001F609 * -<\u00A9 2019 J.M.B., GPLv3\U0001F60E>-";
os << endl;
} else
{
os << UL_LWHITE_BROWN << " * Macht's gut, Kinners! ";
os << LYELLOW_BROWN << "\U0001F609" << UL_LWHITE_BROWN;
os << " * -<\u00A9 2019 J.M.B., GPLv3" << RED_BROWN << "\U0001F60D";
os << UL_LWHITE_BROWN << ">-" << RESET << endl;
}
}
} // Ende: void begruessung (std::ostream& os, bool anfang, std::string prgname)
// * Nun eine Funktion zur Ausgabe von Fehler-Hinweisen:
void meldeInfo (std::ostream& os, bool errMsg, std::string msgStr)
{ using std::endl; // endl bedeutet nun std::endl
if (errMsg) // errMsg = 1: "Fehler: ..."
{ /* ehemals void fehlerInfo (std::ostream& os, std::string fehlerStr) */
if (farbLos)
{
os << " * Fehler: " << msgStr << "!" << endl;
} else
{
os << LRED_BLACK << " * " << UL_LRED_BLACK << "Fehler:" << RESET;
os << " " << msgStr << "!" << endl;
}
} else // errMsg = 0: "Info: ..."
{ /* ehemals void hinweisInfo (std::ostream& os, std::string hinweisStr) */
if (farbLos)
{
os << " * Info: " << msgStr << endl;
} else
{
os << LYELLOW_BROWN << " * " << UL_LYELLOW_BROWN << "Info:" << RESET;
os << " " << msgStr << endl;
}
}
} // Ende: void meldeInfo (std::ostream& os, bool errMsg, std::string msgStr)
void ausgabeInfotext (std::ostream& os, bool hlpMsg)
{
if (hlpMsg) // hlpMsg = 1: Hilfs-Text ..."
{
if (!(farbLos))
os << LYELLOW_BROWN << " * Hilfstext:" << LWHITE_BROWN << "\n";
os << " *******************************************************************\n";
os << " * Generelle Funktion und Spezialparameter des Programms 'example' *\n";
os << " *-===============================================================-*\n";
os << " * Es ist moeglich, als 1. Parameter ein Steuerflag einzugeben: *\n";
os << " * o Keinen Spezialparameter (d.h. kein Steuerflag): *\n";
os << " * Parameter / interaktiv einzugebende Zahlen als Strings holen *\n";
os << " * und nacheinander bearbeiten: jeweils Ganzzahlen zwischen *\n";
os << " * 2 und 18446744073709551615 (2^64-1), auch hex. wie 0x9AFE, *\n";
os << " * in Primfaktoren zerlegen und die Faktoren ausgeben. *\n";
os << " * Alle Nichtzahlen werden ignoriert - sie koennen aber als *\n";
os << " * Zahlentrenner eingesetzt werden (wie 66,0x1B bzw. 66/12/9). *\n";
os << " * Eingabe eines Zeichens: 'H' - Hilfs-, 'V'- Versions-Text und *\n";
os << " * 'B' - beide interaktiv abrufbar, mit '1'/'Q' abbrechen. *\n";
os << " * o -f --file => Ausgabe des Parameter-Teils in eine Datei - *\n";
os << " * eine interaktive Abfrage erfolgt nicht. *\n";
os << " * o -m --mono => Monochromatisch mit Default-Farben vom xterm *\n";
os << " * o -i --inverse => Invertierte Darstellung (mit Nostalgie \U0001F917 ) *\n";
os << " * gelb auf schwarz (wie Turbo Pascal 3.0) *\n";
os << " * o -h --help => Diesen Hilfstext ausgeben und beenden *\n";
os << " * o -v --version => Version, Datum, Autorinfo, Lizenz & beenden *\n";
os << " * o -b -vh -hv => Versions- und Hilfs-Text ausgeben & beenden *\n";
os << " *******************************************************************";
} else // hlpMsg = 1: Versions-Text ..."
{
if (!(farbLos))
os << LYELLOW_BROWN << " * Versionstext:" << LWHITE_BROWN << "\n";
os << " *******************************************************************\n";
os << " * C++-Programm fuer GNU/Linux >example< in Version 2.00 (Phase 2) *\n";
os << " * \u00A9 2019 J.M.B. (URL: https://www.jmb-edu.de/) 03.09.2019 GPLv3 *\n";
os << " * [URL: https://www.jmb-edu.de/cpp_programming.html#progcppexamp] *\n";
os << " *******************************************************************";
}
if (!(farbLos))
os << RESET;
os << std::endl;
} // Ende: void ausgabeInfotext (std::ostream& os)
// * Globale Variable fuer Dateiname
std::string outputFilename = ""; // v- spaeter mit Zeitstempel YYYYMMDDHHMMSS..
std::string myOutputFilename = "PrimZahlZerlegung_JMB.txt";// Ueberschreibschutz
// * Zwei Funktionen zum Erhalt des Datumsstrings (braucht '# include <ctime>'):
std::string addZeroIOD (std::ostream& os, std::string addStr)
{
if (addStr.length() == 1)
{
addStr = std::string("0")+addStr; // ergaenze fuehrende 0 bei einer Ziffer
} else if ((addStr.length() == 0) || (addStr.length() > 2)) // 2 ist OK :)
{
meldeInfo (os, 1, "Falsche Stringlaenge in addZeroIOD!");
return ""; // macht nichts kaputt - Fehler sichtbar
}
return addStr;
} // Ende: addZeroIOD (std::ostream& os, std::string addStr)
std::string getDatStr (std::ostream& os)
{ using namespace std; // sollte vermieden werden; hier klein
tm *nun; // ein struct fuer Zeitangaben: tm_*
time_t now = time(0); // Sekunden seit 00:00, Jan 1 1970 UTC
nun = localtime(&now); // Konvertieren in Kalenderzeit
int dateYear = 1900 + nun->tm_year; // Jahr: seit 1900 (= 0)
int dateMonth = 1 + nun->tm_mon; // Monate: 0-11
int dateDay = nun->tm_mday; // Tage: 1-31
int timeHour = nun->tm_hour; // Stunden: 0-23
int timeMin = nun->tm_min; // Minuten: 0-59
int timeSec = nun->tm_sec; // Sekunden: 0-60 (Schaltsekunde)
string dateTime = to_string (dateYear); // Start dateTime mit Jahreszahl
string addStr = addZeroIOD (os, to_string (dateMonth)); // Monat zweist. ..
dateTime += addStr; // .. in addStr und diesen anfuegen
addStr = addZeroIOD(os, to_string (dateDay)); // Tag zweistellig ..
dateTime += addStr; // .. in addStr und diesen anfuegen
addStr = addZeroIOD(os, to_string (timeHour)); // Stunden zweistellig ..
dateTime += addStr; // .. in addStr und diesen anfuegen
addStr = addZeroIOD(os, to_string (timeMin)); // Minuten zweistellig ..
dateTime += addStr; // .. in addStr und diesen anfuegen
addStr = addZeroIOD(os, to_string (timeSec)); // Sekunden zweistellig ..
dateTime += addStr; // .. in addStr und diesen anfuegen
return dateTime; // Zeitstring als YYYYMMDDHHMMSS zurueck
} // Ende: std::string getDatStr (std::ostream& os)
// * Globale Variable fuer Primfaktorliste:
// * Funktion suchePrimFaktoren bestueckt sie,
// * Funktion ausgabePrimFaktoren liest sie
// * fuer Ausgabe aus und setzt sie zurueck.
std::vector<unsigned long long> wertepfs;
// * Globale Variable, die bei ausgabePrimFaktoren ausgelesen und
// * ausgegeben wird und an deren Ende auch inkrementiert (+1) wird.
unsigned long long anzFaktorZerlegungen = 1;
// * Globale Variablen fuer Eingabe ueber Parameter/Tastatur ...
std::string inputStr = ""; // Einlese-String
std::string::size_type sz = 0; // Entspricht size_t (ein Alias)
// sz dient als Marker fuer StringRest-Kopie in verwandleStringInULL !
// * Funktion zur PF-Ermittlung - der eigentliche Algorithmus (d.h. das Herz)
void suchePrimFaktoren (unsigned long long n)
{
/* 1. Schritt: */
// Anzahl 2-en ausgeben, durch die n (vor 1. Schritt) dividiert werden kann
while (n%2 == 0) // wenn bei Division kein Rest
{
wertepfs.push_back (2); // jeder Faktor wird gemerkt -> wertepfs
n = n/2;
}
/* 2. Schritt: */
// n (Anfang 2. Schritt) muss nun ungerade sein - Primfaktoren 2 wurden
// entdeckt, somit kann man immer eine Zahl uebergehen, daher i=i+2
for (unsigned long long i = 3; i <= std::sqrt(n); i = i+2)
{ // .. nach GCC Namspace-Fix sqrtl statt^^^^ verwenden (C++17-Voraussetzung)
// Solange n durch i teilbar ist, wird i ausgegeben (analog 2 oben)
while (n%i == 0) // wenn bei Division kein Rest
{
wertepfs.push_back (i); // jeder Faktor wird gemerkt -> wertepfs
n = n/i;
}
}
/* 3. Schritt: */
// Wenn for bis i = Wurzel n (n nach 1. Schritt) nicht n=1 (Ende 2. Schritt)
// liefert, muss n der letzte fehlende Primfaktor der Zerlegung sein
if (n > 2) // n ist der letzte fehlende PF ...
{
wertepfs.push_back (n); // n wird als PF gemerkt -> wertepfs
}
} // Ende: void suchePrimFaktoren (unsigned long long n)
void ausgabePrimFaktoren (std::ostream& os, unsigned long long wert)
{
int pfanz = 0; // Anzahl Primfaktoren - hier int OK!
std::string pfliststring = " "; // Def.+Initialisierung von String
std::string dummystring = "";
unsigned int curoutstrllength = 0; // Laenge der aktuellen pfliststring-Z.
unsigned int addfutstrlength= 0; // Laenge der naechsten Ergaenzung
const unsigned int maxlength = 75; // Angabe der maximalen Zeilenlaenge - 1
std::string zeilUmbrStr = ",\n * ";
if (!(farbLos))
zeilUmbrStr = ",\n"+LYELLOW_BROWN+" * "+RESET+" ";
for (unsigned long long primfaktor : wertepfs)
{
if (pfanz < 1)
{
pfliststring += std::to_string (primfaktor); // to_string ab C++11
curoutstrllength = pfliststring.length(); // Startlaenge der Zeile
} else // es gab Vorgaenger: +' ,'
{
dummystring = std::to_string (primfaktor);
addfutstrlength = (2+dummystring.length());
if (!(curoutstrllength+addfutstrlength+2 < maxlength))
{
pfliststring += zeilUmbrStr; // Zeilenumbruch + Platz
curoutstrllength = addfutstrlength; // Neuer Start Zeilenlaenge
} else
{
pfliststring += ", "; // Komma + wenig Platz
curoutstrllength += addfutstrlength; // Zeilenlaenge vergroess.
}
pfliststring += std::to_string (primfaktor); // aktuelle PF dem Str. zuf.
}
++pfanz;
}
pfliststring += "."; // Abschlusspunkt
if (pfanz < 2)
{
if (!(farbLos))
{
os << LYELLOW_BROWN << " * " << RESET;
} else
{
os << " * ";
}
os << "Der " << anzFaktorZerlegungen << ". Wert '" << wert;
os << "' ist bereits prim." << std::endl; // \n und Flushen am Schluss
} else
{
if (!(farbLos))
{
os << LYELLOW_BROWN << " * " << RESET;
} else
{
os << " * ";
}
os << " Der " << anzFaktorZerlegungen << ". Wert '" << wert;
os << "' konnte in " << pfanz << " Primfaktoren zerlegt werden:\n";
if (!(farbLos))
{
os << LYELLOW_BROWN << " * " << RESET;
} else
{
os << " * ";
}
os << pfliststring << std::endl; // Liste als Abschluss, \n und Flushen!
} // Angaben x86_64-Linux, signed|uns. int|long|long long ist systemabhaengig:
if (wert == 18446744073709551615ull)// 2^64-1 groesster 64 Bit - Wert!
{
meldeInfo (os, 0, "Ende von 'unsigned long long' erreicht - groesser nur mit Spezial-Libs!");
} else if (wert > 9223372036854775807) // 2^63-1 grosster signed 64 Bit - W!
{
meldeInfo (os, 0, "Hier war 'unsigned long long' statt '>long long<' notwendig!");
} else if (wert > 4294967295) // 2^32-1 grosster unsigned 32 Bit-W!
{
meldeInfo (os, 0, "Hier war 'unsigned long long' statt '>unsigned int<' notwendig!");
} else if (wert > 2147483647) // 2^31-1 grosster signed 32 Bit-W!
{
meldeInfo (os, 0, "Hier war 'unsigned long long' statt '>int<' notwendig!");
} else if (wert > 255) // 2^8-1 grosster unsigned 8 Bit-W!
{
meldeInfo (os, 0, "Hier war 'unsigned long long' statt '>unsigned char<' notwendig!");
} else if (wert > 127) // 2^7-1 grosster signed 8 Bit-W!
{
meldeInfo (os, 0, "Hier war 'unsigned long long' statt '>signed char<' notwendig!");
}
/* Vector wertepfs loeschen, damit Platz fuer neue Eintraege ist */
wertepfs.clear();
++anzFaktorZerlegungen; // Globale Variable als Zaehler: +1
} // Ende: void ausgabePrimFaktoren (std::ostream& os, unsigned long long wert)
// * Diese Funktion loescht fuehrende Zahlen (zu gross fuer ULL), indem diese
// * im Uebergabestring geloescht werden und der Rest uebergeben wird.
// * Fuer vorzeichenlose Ganzzahl-Typen ist die Funktion schon allgemein.
std::string loescheFuehrendeZahlen (std::ostream& os, std::string stringRest)
{
unsigned int stringRestLength = stringRest.length(); // Laenge stringRest
if (stringRestLength == 0)
{ // die Funktion kann mit Leerstring starten und damit enden - kein Fehler!
meldeInfo (os, 1, "Leerstring bei loescheFuehrendeZahlen sollte nicht vorkommen");
return "";
}
if (!(std::isdigit(stringRest[0])))
{
meldeInfo (os, 1, "Aufruf von loescheFuehrendeZahlen mit 1. Zeichen keine Zahl");
return stringRest; // Parameter startet mit Zahl - nix tun
} else
{ // 1. Zeichen [0] wird geloescht - mehr?
for (unsigned int i = 1; i < stringRestLength; ++i)
{ // wieviele Zeichen werden geloescht: i
if (!(std::isdigit(stringRest[i]))) // keine Zahl, dann hier Abbruch
{
return (stringRest.erase(0, i)); // ab 0 {= Anfang}: i Zeichen loeschen
}
}
return ""; // alle Zeichen Zahlen - Leerstring
}
} // Ende: string loescheFuehrendeZahlen (ostream& os, std::string stringRest)
// * Diese Funktion loescht fuehrende Nicht-Zahlen, indem diese im
// * Uebergabestring geloescht werden und der Rest uebergeben wird.
// * Fuer vorzeichenlose Ganzzahl-Typen ist die Funktion schon allgemein,
// * wenn man nicht strenger mit dem Anwender sein will/muss. ;)
std::string loescheFuehrendeNichtZahlen (std::ostream& os, std::string stringRest)
{
unsigned int stringRestLength = stringRest.length(); // Laenge stringRest
if (stringRestLength == 0)
{ // die Funktion kann mit Leerstring starten und damit enden - kein Fehler!
return "";
}
if (std::isdigit(stringRest[0]))
{
return stringRest; // Parameter startet mit Zahl - nix tun
} else
{ // 1. Zeichen [0] wird geloescht - mehr?
if ((stringRest[0] == '-') && (std::isdigit(stringRest[1])))
meldeInfo (os, 1, "Negative Zahlen sind nicht erlaubt: '-' wird verworfen");
for (unsigned int i = 1; i < stringRestLength; ++i)
{ // wieviele Zeichen werden geloescht: i
if (std::isdigit(stringRest[i]))
{
return (stringRest.erase(0, i)); // ab 0 {= Anfang}: i Zeichen loeschen
} else if ((stringRest[i] == '-') && (std::isdigit(stringRest[(i+1)])))
{ // nur bei - Meldung - Rest stumm weg
meldeInfo (os, 1, "Negative Zahlen sind nicht erlaubt: '-' wird verworfen");
} // alles andere wird uebergangen
}
return ""; // alle Zeichen keine Zahlen - Leerstr.
}
} // Ende: string loescheFuehrendeNichtZahlen (ostream& os, string stringRest)
// * Diese Funktion wandelt einen String in die zugehoerige ULL
// * (groesster positiver C++-Standard-Ganzzahltyp) und faengt
// * alle Probleme ab - da negative Werte ohne jede Kennzeichnung
// * unsinnig konvertiert werden, wird zur Eliminierung von '-'
// * die obige Funktion loescheFuehrendeNichtZahlen vorgeschaltet.
// * Sollte diese Funktion in anderem Zusammenhang verwendet werden,
// * darf nicht mehr 0 angemahnt und ansonsten zum Weitermachen verwendet
// * werden, sondern sollte ueber einen Fehlerstatus weitergegeben werden,
// * der ggf. eine globale Variable ist als ullConvErr oder ULL global und
// * den Boolean als Rueckgabe, da eine Funktion nur einen Rueckgabewert
// * hat (wenn man kein Konstrukt uebergeben will) - zudem sollte als
// * Parameter einfach "(std::string teilString)" mitgegeben werden - hier
// * werden globale Variablen wegen komplexer KBD-Schleife verwendet ... -
// * und der Reststring wird in dieser Funktion mit sz beschnittet ... -
// * ansonsten ist die Funktion bereits allgemein.
unsigned long long verwandleStringInULL (std::ostream& os)
{
unsigned long long wert = 0; // Definition mit Startwert: Rueckgabe
try // Solange kein Fehlert auftritt ...
{
wert = std::stoull (inputStr,&sz,0); // ... sollte dies die Zahl sein.
if (wert == 0) // 0 wird sonst verwendet als 'continue'
{
meldeInfo (os, 1, "Es wurde '0' eingegeben"); // 0 bei Faktorzerlegung unsinnig
}
} catch (std::invalid_argument &exc) // --- Erster Handler ...
{
meldeInfo (os, 1, "Ungueltiger Aufrufparameter: nicht in ULL konvertierbar");
inputStr = loescheFuehrendeZahlen(os, inputStr);
return 0; // hier abbrechen, aussen weitermachen
} catch (std::out_of_range &exc) // --- zweiter Handler ...
{ // bei ULL bedeutet ^- dies zu gross - negativ wird nicht erkannt!
meldeInfo (os, 1, "Ungueltiger Aufrufparameter: ausserhalb der ULL-Grenzen (zu gross)");
inputStr = loescheFuehrendeZahlen(os, inputStr);
return 0; // hier abbrechen, aussen weitermachen
} catch( ... ) // ... dritter Handler fuer den Rest.
{
meldeInfo (os, 1, "Seltsames Problem bei der Umwandlung in ULL-Grenzen aufgetreten");
inputStr = loescheFuehrendeZahlen(os, inputStr);
return 0; // hier abbrechen, aussen weitermachen
}
// Nur Loeschen der Zahl bei Ueberlauf/Umwandlung verlaesst zuvor - return 0:
inputStr = inputStr.substr(sz); // inputStr ist nun der Rest ...
return wert;
} // Ende: unsigned long long verwandleStringInULL (std::ostream& os)
// * Nun zwei Funktionen, zuerst werden Kommandozeilen-Parameter gesucht (CLP),
// * dann wird eine Eingabe ueber die Tastatur erbeten und gelesen (KBD).
// * Wegen der zentralen Schleifen stehen sie direkt vor main ...
// Diese Funktion ermittelt die Parameter und wertet diese einzeln als String
// aus, die in jeweils eine oder mehrere Zahlen ueberfuehrt werden,
// die in einer Schleife abgearbeitet werden:
// sie sollen in Primfaktoren zerlegt und so ausgegeben werden.
unsigned long long eingabeCLPZahlZumFaktorisieren (std::ostream& os, int argc,
const char* argv[], bool frstParamUsed)
{
unsigned long long wert = 0; // < 2 ist Fehlercode, > 1 ist ges. Wert
for (int i = 1; i < argc; ++i)
{
if ((i == 1) && (frstParamUsed)) // 1. Parameter "-f" wegwerfen!
{
meldeInfo (os, 0, "1. Parameter enthielt Steuerflag - ist kein Input.");
continue;
}
inputStr = argv[i]; // fuer meine Funktionen editierbar als std::string
// * String muss mit Zahl beginnen, kein '-' oder gar Buchstabe:
inputStr = loescheFuehrendeNichtZahlen (os, inputStr);
while (!inputStr.empty())
{
wert = verwandleStringInULL (os); // inputStr wird verwendet
// * Bedeutet: std::stoull (dummyString,&sz,0) & inputStr.substr(0,sz) kopiert.
if (wert > 1) // OK, wert kann zerlegt werden
{
/* PFs ermitteln und in vector wertepfs speichern */
suchePrimFaktoren (wert);
/* PFs aus wertepfs lesen, mit "," getrennt ausgeben & "." am Ende */
ausgabePrimFaktoren (os, wert);
} else if (wert == 1) // wegen Benchmark auch hier Abbruch
{
meldeInfo (os, 0, "Abbruch des Programms wurde gewuenscht! - Benchmark?");
return 0; // Programmabbruch mit OK-Code gewuenscht
} // = 0 wird nicht behandelt, da verwandleStringInULL Fehler meldet
// * String muss mit Zahl beginnen, kein '-' oder gar Buchstabe:
inputStr = loescheFuehrendeNichtZahlen (os, inputStr);
}
}
if (wert == 0) // wenn nicht ueber return: continue
wert = 5; // uninteressanter wird - unbeachtet
return wert; // Weitergabe der Zahl ...
} // Ende: unsigned long long eingabeCLPZahlZumFaktorisieren (std::ostream& os,
// \ int argc, const char* argv[], bool frstParamUsed)
// Diese Funktion liest bei Bedarf einen Sting, der in eine oder mehrere
// Zahlen ueberfuehrt wird, die in einer Schleife abgearbeitet werden:
// sie sollen in Primfaktoren zerlegt und so ausgegeben werden.
unsigned long long eingabeKBDZahlZumFaktorisieren (std::ostream& os)
{
unsigned long long wert = 0; // < 1 ist falsch - d.h. wiederholen,
// 1 ist Fehlercode zum Programmabbruch,
// > 1 ist gesuchter Wert!
while (wert < 1) // Bis wert mindestens 1 ist einlesen
{
inputStr = "";
// * Eingabe-Aufforderung:
meldeInfo (os, 0, "Spezial: 'H': Hilfe \U0001F198-'B'-'V': Versionsinfo \U0001F6C8 , '1'/'Q': Abbruch \u274C.");
meldeInfo (os, 0, "Gib ansonsten eine ganze Zahl \u2115 in [2;18446744073709551615]\u2705 ein:");
if (farbLos)
{
os << " * ";
} else
{
os << LYELLOW_BROWN << " * " << RESET;
}
os << " \U0001F644 \U0001F635";
os << " \U0001F634 \U0001F612 ";
// * Lese von Tastatur in String:
std::getline(std::cin, inputStr);
if (inputStr.length() == 1)
{
switch (inputStr[0])
{
case 'H': case 'h':
{ // * Hilfsinfo und Abbruch der Funktion mit '5' {= continue}
ausgabeInfotext (os, 1);
return 5;
}
case 'V': case 'v':
{ // * Versionsinfo und Abbruch der Funktion mit '5' {= continue}
ausgabeInfotext (os, 0);
return 5;
}
case 'B': case 'b':
{ // * Versionsinfo und Abbruch der Funktion mit '5' {= continue}
ausgabeInfotext (os, 0);
ausgabeInfotext (os, 1);
return 5;
}
case '1': case 'Q': case 'q':
{ // * Programm-Abbruch: '1' - break kann (wie zuvor: '5') entfallen.
return 0;
} // ein Zweig: 'default : ...' als Joker ist nicht noetig.
}
}
// * String muss mit Zahl beginnen, kein '-' oder gar Buchstabe:
inputStr = loescheFuehrendeNichtZahlen (os, inputStr);
while (!inputStr.empty())
{
wert = verwandleStringInULL (os); // inputStr wird verwendet
// * Bedeutet: std::stoull (dummyString,&sz,0) & inputStr.substr(0,sz) kopiert.
if (wert > 1) // OK, wert kann zerlegt werden
{
/* PFs ermitteln und in vector wertepfs speichern */
suchePrimFaktoren (wert);
/* PFs aus wertepfs lesen, mit "," getrennt ausgeben und "." am Ende */
ausgabePrimFaktoren (os, wert);
} else if (wert == 1)
{
meldeInfo (os, 0, "Abbruch des Programms wurde gewuenscht!");
break;
} // = 0 wird nicht behandelt, da verwandleStringInULL Fehler meldet
// * String muss mit Zahl beginnen, kein '-' oder gar Buchstabe:
inputStr = loescheFuehrendeNichtZahlen (os, inputStr);
}
}
if (wert == 1)
{
wert = 0;
}
return wert; // Weitergabe der Zahl zur Faktorisierung
} // Ende: unsigned long long eingabeKBDZahlZumFaktorisieren (std::ostream& os)
// * Die folgende Funktion enthaelt den Grossteil des ehemaligen Kerns
// * von main, der wegen Uebergabe von ostream nun besser als Funktion
// * aufgerufen werden kann.
// * Es wird die Hauptfunktion als CLP = Parameter-Abfrage und als Schleife
// * KBD als interaktive Tastaturabfrage behandelt und Return-Codes ermittelt.
int abfrageSchleifePFBestimmungAusgabe (std::ostream& os, const int argc,
const char* argv[], bool frstParamUsed)
{
/* Zahl aus Kommandozeilen-Parameter ermitteln,
die im Anschluss in PFs aufgespalten werden soll */
unsigned long long wert = eingabeCLPZahlZumFaktorisieren (os, argc, argv, frstParamUsed);
// * Variablen-Deklaration von wert als Rueckgabewert der beiden
// * Eingabefunktionen; in abfrageSchleifePFBestimmungAusgabe bedeutet:
// * '> 1': continue (Programm laeuft weiter - Tastatureingabe-Schleife),
// * '== 1': Abbruch mit Fehlercode 1 und
// * '== 0': Abbruch gewuenscht, d.h. mit Code 0 fuer alles OK!
// CLP-Einlesen nun beendet ... noch die letzten Auswertungen von wert
if (outputFilename == myOutputFilename)
{ // * Datei-Ausgabe hat keinen KBD-Teil
if (wert > 1) // Keine Abbruchbedingung bislang,
wert = 0; // also regulaeres Ende
meldeInfo (os, 0, "Hier noch zum Abschluss der Versions- und Hilfs-Text des Programms:");
ausgabeInfotext (os, 0); // Versions-Text ausgeben
ausgabeInfotext (os, 1); // Hilfs-Text ausgeben
return wert; // Verabschiedung erfolgt im main-Zweig
}
if (wert == 0) // {(wert < 2): return (wert) ginge auch}
{ // * Abbruch nach CLP gewuenscht (kein KBD) - Benchmark
return 0; // dann Abbruch mit Fehlercode 0
} else if (wert == 1)
{ // Wesentliches Problem
return 1; // dann Abbruch mit Fehlercode 1
} // ausser 0 und 1 bedeutet alles continue
do // Schleife bzgl. Tastatureingabe ...
{
/* Zahl aus Tastatureingabe (KBD; von cin) ermitteln,
die im Anschluss in PFs aufgespalten werden soll */
wert = eingabeKBDZahlZumFaktorisieren (os);
if (wert == 1) // Wesentliches Problem
return 1; // dann Abbruch mit Fehlercode 1
if (wert == 0) // Abbruch durch Eingabe 1 gewaehlt
return 0; // -> Abbruch ohne Fehlercode (0 = OK)
// * Zur Erinnerung, main verabschiedet (ausser Dateiausgabe) und reicht
// * am Ende den Return-Code an das Betriebssystem/xterm/Shell weiter ...
} while (wert > 1); // gleichbedeutend mit !(wert == 1),
// und dies sollte oben abbrechen ...
// *** HIER SOLLTE NICHTS LANDEN - EINFACH DURCHSCHAUEN ...
meldeInfo (os, 1, "Hier sollte - am Ende von abfrageSchleifePFBestimmungAusgabe - nichts landen");
return 1; // Uebergabewert (= Fehlercode) an main
} // Ende: int abfrageSchleifePFBestimmungAusgabe (ostream& os, const int argc,
// \ const char* argv[], bool frstParamUsed)
// * Hauptfunktion - nimmt Parameter entgegen und ermittelt ggf. einen
// * Steuer-Parameter, aendert ggf. die globale Variable farbLos und setzt
// * ggf. die an CLP durchgereichte Variable frstParamUsed (beides passiert
// * nur hier), gibt dann viele Parameter wie genauer outputstream und
// * Parameter an die Steuerfunktion abfrageSchleifePFBestimmungAusgabe
// * weiter, die die eigentliche Programmfunktionalitaet ausloest und
// * die Return-Codes liefert.
// * Im wesentlichen kuemmert sich main um die Aenderung von ostream fuer
// * unterschiedliche Ausgaben: neben cout (7. Moeglichkeit, und mit
// * Farbaenderungen auch 2.+3. Moeglichkeit) und Datei (1. Moeglichkeit)
// * waere auch in einen String denkbar, was hier eher stoeren wuerde,
// * zu Testzwecken aber praktisch ist ...:
// * ``std::ostringstream oss{};'', so dass dieser abgfragt werden kann:
// * ``if (oss.str() == "...") { ... }''.
int main (int argc, const char* argv[])
{ // Hauptfunktion mit Aufruf-Parametern
try // Absichern gegenueber Exceptions ...
{
std::string prgname = argv[0]; // Aufrufname des Programms
std::string frstParamStr = "";
bool frstParamUsed = 0; // neue bool an CLP: 1. Param. continue
int retStat = 0; // Fehlercode an OS/xterm/shell
// nach Parameter fragen bzgl. output - bool fileOut setzen!
if (argc > 1) // mindestens ein Parameter gegeben ...
frstParamStr = argv[1]; // String hat 1. Parameter oder ist leer
if ((frstParamStr == "-f") || (frstParamStr == "--file"))
{ // * 1. Moeglichkeit: Ausgabe in Datei
frstParamUsed = 1; // 1. Parameter wurde verwendet
/* Begruessung */ // Erst auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // .. Begruessung
myOutputFilename = std::string("PrimZahlZerlegung_")+
getDatStr(std::cout)+std::string("_JMB.txt");
outputFilename = myOutputFilename;
meldeInfo (std::cout, 0, "Die wirkliche Ausgabe erfolgt nun ueber die Datei:");
meldeInfo (std::cout, 0, std::string(" * '")+outputFilename+std::string("'!"));
farbLos = true; // keine ANSI-Farben
std::ofstream datei {outputFilename};
// Datei outputFilename -^ wird neu erzeugt oder bei Existenz
// ueberschrieben (daher ggf. sinnvoller mit Zeitstempel im Namen);
// dass Oeffnen und Schliessen ueberlaesst man sicherheitshalber
// den Mechanismen von ofstream (Konstruktor und Destruktor) - AWG!
/* Begruessung */ // .. nun auch in die Datei
begruessung (datei, 1, prgname);
meldeInfo (datei, 0, std::string("Diese Ausgabe-Datei heisst: '")+outputFilename+std::string("'!"));
/* Hauptteil */
retStat = abfrageSchleifePFBestimmungAusgabe (datei, argc, argv, frstParamUsed);
if (anzFaktorZerlegungen == 1)
{ // Info, wenn Primfaktoren ueberhaupt berechnet werden sollten
meldeInfo (datei, 1, "Es konnte keine sinnvolle Eingabe gefunden werden");
}
/* Verabschiedung */ // erst in die Datei ..
begruessung (datei, 0, prgname); // Verabschiedung
farbLos = false; // nun wieder mit ANSI-Farben
if (anzFaktorZerlegungen == 1)
{ // Info, wenn Primfaktoren ueberhaupt berechnet werden sollten
meldeInfo (std::cout, 1, "Es konnte keine sinnvolle Eingabe gefunden werden");
}
/* Verabschiedung */ // nun auch auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Verabschiedung
} else if ((frstParamStr == "-m") || (frstParamStr == "--mono"))
{ // * 2. Moeglichkeit: monochromatische Darstellung - Default von xterm
frstParamUsed = 1; // 1. Parameter wurde verwendet
farbLos = true; // keine ANSI-Farben
/* Begruessung */ // Auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // Begruessung monochrom
meldeInfo (std::cout, 0, "Die wirkliche Ausgabe erfolgt nun monochromatisch:");
/* Hauptteil */
retStat = abfrageSchleifePFBestimmungAusgabe (std::cout, argc, argv, frstParamUsed);
if (anzFaktorZerlegungen == 1)
{ // Info, wenn Primfaktoren ueberhaupt berechnet werden sollten
meldeInfo (std::cout, 1, "Es konnte keine sinnvolle Eingabe gefunden werden");
}
/* Verabschiedung */ // Auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Abschied monochrom
} else if ((frstParamStr == "-i") || (frstParamStr == "--inverse"))
{ // * 3. Moeglichkeit: inverse Darstellung (gelb auf schwarz - Tur.Pascal3)
frstParamUsed = 1; // 1. Parameter wurde verwendet
farbLos = true; // keine ANSI-Farben
std::cout << LYELLOW_BLACK << "\n";
/* Begruessung */ // Auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // Begruessung invers
meldeInfo (std::cout, 0, "Die wirkliche Ausgabe erfolgt nun invers:");
/* Hauptteil */
retStat = abfrageSchleifePFBestimmungAusgabe (std::cout, argc, argv, frstParamUsed);
if (anzFaktorZerlegungen == 1)
{ // Info, wenn Primfaktoren ueberhaupt berechnet werden sollten
meldeInfo (std::cout, 1, "Es konnte keine sinnvolle Eingabe gefunden werden");
}
/* Verabschiedung */ // Auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Abschied invers
std::cout << RESET << std::endl;
} else if ((frstParamStr == "-h") || (frstParamStr == "--help"))
{ // * 4. Moeglichkeit: Hilfstext
frstParamUsed = 1; // 1. Parameter wurde verwendet
std::cout << CLRSCR; // Bildschirm loeschen
/* Begruessung */ // Auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // Begruessung zur Hilfe
/* Hilfstext-Ausgabe */
ausgabeInfotext (std::cout, 1); // Hilfs-Text ausgeben
meldeInfo (std::cout, 0, "Ende Hilfs-Text.");
/* Verabschiedung */ // Auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Abschied von Hilfe
} else if ((frstParamStr == "-v") || (frstParamStr == "--version"))
{ // * 5. Moeglichkeit: Versionsinfo
frstParamUsed = 1; // 1. Parameter wurde verwendet
std::cout << CLRSCR; // Bildschirm loeschen
/* Begruessung */ // Auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // Begruessung zum Versionstext
/* Versions-Ausgabe */
ausgabeInfotext (std::cout, 0); // Versions-Text ausgeben
meldeInfo (std::cout, 0, "Ende Versions-Text.");
/* Verabschiedung */ // Auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Abschied vom Versionstext
} else if ((frstParamStr == "-b") || (frstParamStr == "-vh") || (frstParamStr == "-hv"))
{ // * 6. Moeglichkeit: Versions- und Hilfs-Text
frstParamUsed = 1; // 1. Parameter wurde verwendet
std::cout << CLRSCR; // Bildschirm loeschen
/* Begruessung */ // Auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // Begruessung zur vollen Info
/* Versions-Ausgabe */
ausgabeInfotext (std::cout, 0); // Versions-Text ausgeben
/* Hilfstext-Ausgabe */
ausgabeInfotext (std::cout, 1); // Hilfs-Text ausgeben
meldeInfo (std::cout, 0, "Ende Versions- und Hilfs-Text.");
/* Verabschiedung */ // Auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Abschied von vollen Info
} else
{ // * 7. Moeglichkeit: Bildschirm - Standard {= Default}, ohne Spezial-Par.
farbLos = false; // Abschluss auf cout mit ANSI-Farben
/* Begruessung */ // Auf den Bildschirm ..
begruessung (std::cout, 1, prgname); // Begruessung zum Standardprogramm
meldeInfo (std::cout, 0, "Die gesamte Ausgabe erfolgt auf dem Bildschirm ...");
/* Hauptteil */
retStat = abfrageSchleifePFBestimmungAusgabe (std::cout, argc, argv, frstParamUsed);
if (anzFaktorZerlegungen == 1)
{ // Info, wenn Primfaktoren ueberhaupt berechnet werden sollten
meldeInfo (std::cout, 1, "Es konnte keine sinnvolle Eingabe gefunden werden");
}
/* Verabschiedung */ // Auf den Bildschirm ..
begruessung (std::cout, 0, prgname); // Abschied vom Standardprogramm
}
return retStat; // Programm-Ende mit Fehlercode-Rueckgabe
} catch (...) // Ende des try-Blocks zur Ausnahme-Beh.
{ // Behandlung der Ausnahmebedingung ...
meldeInfo (std::cout, 1, "Das Programm fand eine seltsame Ausnahmebedingung in main");
if (anzFaktorZerlegungen == 1)
meldeInfo (std::cout, 1, "Es konnte keine sinnvolle Eingabe gefunden werden");
return 1;
}
meldeInfo (std::cout, 1, "Das Programm sollte nicht an diese Stelle gelangen");
} // Ende: int main (int argc, const char* argv[])
/******************************************************************************
* Das war's - ein erstes Hobby - C++ - Programm - nicht zu trivial ... :)) *
******************************************************************************
*/
Erläuterung zum Quelltext
✯ Neu 09/2019 ✯
Die Phase 2 wurde am 03.09.2019 abgeschlossen –
der neue Quellcode (vergrößert von 104
auf aktuell 775 Zeilen;
also wieder größer als das
bereits am 23.08.2019
überarbeitete Makefile 😳 ; von 41
auf nun 139 Zeilen
und auch größer als die GPLv3‑Lizenz mit 674 Zeilen)
mit den Erklärungen
ist nun hier zu finden ...
und es hat sich viel geändert:
Umstellen auf unsigned long long
zur Zerlegung größerer Zahlen,
Abfangen von (ich hoffe 😀 )
allen Eingabefehlern,
Ausgabeumleitung inkl. Schreiben in eine Datei
mit genauem Zeitstempel im Namen,
viele Flags z.B. mit inverser oder
monochromer Bildschirmausgabe,
Ausgabe eines Hilfstextes und ANSI-Steuercodes
über konstante String-Variablen,
übersichtlichere Ausgabe der Primfaktoren,
flexiblere Eingabe mit beliebigen Trennzeichen
sowie erweiterte Kommentare ...
Das Programm ist mit Phase 2 weit genug gediehen,
um damit einen C++-Einstiegskurs sinnvoll leiten
zu können. 😤
Da die Phase 1
deutlich kompakter ist,
kann diese auch zuerst gelesen werden,
erst danach die deutlich erweiterte Fassung und
Erklärung zu Phase 2 hier.
Es gibt einiges zu beachten, bis man
mit dem Quelltext etwas anfangen kann:
- Kommentare:
Alles von //
bis zum Zeilenende wird vom Compiler ignoriert
(z.B. Zeilen 39‑42 oder 43),
ebenso alles zwischen /* und */
(z.B. Zeilen 1‑14 oder Zeile 93;
vgl. Kommentar‑Arten unten).
Hier sollen Kommentare verwendet werden,
die den Quelltext auch nach Monaten
bis Jahren schnell verständlich machen sollen.
Man sollte sich merken, dass bei C und C++
als Kommentar immer der Slash / mit einem weiteren Zeichen
(genauer // bzw.
/* ... */)
kombiniert wird –
bei Shell-Skripten bzw. Makefiles ist es
das Doppelkreuz (oder hash) #, bei 📜LATEX
das Prozentzeichen %,
bei 🌐HTML
<!-- ... -->
(vgl. Kommentarbeispiele
aus Wikipedia).
- Hauptteil: Jedes C++/C‑Programm
enthält genau eine main-Funktion
(im obigen Beispiel Zeile 635;
hier in der komplizierten Fassung
unter Heranziehen von mit dem Aufruf
mitgegebenen Parametern).
Diese Funktion entspricht
dem aufgerufenen Programm –
alles weitere muss von dort aufgerufen werden,
wie im Beispiel die Funktion begruessung
(in Zeile 650+663+672+679+685+694+701+710+717+722+728+733+739+746+751+760, die Funktion selbst
ist in Zeilen 58‑87 zu finden)
oder auch der überweigende Bestandteil von main aus Phase 1:
abfrageSchleifePFBestimmungAusgabe
(in Zeilen 666+688+704+754,
die Funktion selbst ist in Zeilen 569‑619
zu finden) und dem dortigen Aufruf
deren beider Unterfunktionen zum Einlesen
von Parametern eingabeCLPZahlZumFaktorisieren
(in Zeile 579, die Funktion selbst
ist in Zeilen 443‑488 zu finden) und
von Tastatureingaben eingabeKBDZahlZumFaktorisieren
(in Zeile 606, die Funktion selbst
ist in Zeilen 490‑567 zu finden),
da das neue main vorrangig die Betriebsart und
damit auch die Datenausgabe an Bildschirm oder
in eine Datei steuert (in einen String
wäre zu Testzwecken auch ostringstream denkbar
(wie im Kommentar in Zeilen 628‑634
angedeutet) – hier machte dies
wenig Sinn).
Will man Aufrufparameter ignorieren, reicht ein einfaches:
int main () // Hauptfunktion ohne Aufruf-Parameter
Die Hauptfunktion main sollte
mit return 0
abgebrochen werden, was das sofortige Programmende
bedeutet mit Übergabewert 0
für alles OK, jede andere Zahl (aus
Kompatibilitätsgründen besser nur bis 127, zumeist aber 1, bedeutet einen Fehler{code},
den man in der Shell [unter Linux meist
die Bash (26.09.2022: Bash 5.2),
zu überprüfen
über echo $SHELL
mit typischer Ausgabe:
/bin/bash] aufrufen kann:
./example; echo
"Fehlercode: "$?).
- Präprozessor: Alle Zeilen,
die mit Doppelkreuz #
beginnen, werden vom Präprozessor ausgeführt,
noch bevor der Compiler seine Arbeit aufnimmt.
#include weist diesen an,
die anzugebende Standard-Bibliothek
(im obigen Beispiel Zeilen 14‑25;
hier mit im Kommentar
angegebenem Verwendungszweck; diese Dateien sollten sich
im Suchpfad des Compilers befinden) oder auch
eine weitere Quelltextdatei im aktuellen Verzeichnis
(#include "meinModul.hpp";
also doppelte Anführungszeichen
statt spitze Klammern)
einzubinden.
In C++20 werden Möglichkeiten eingeführt,
auch hier den Präprozessor obslet zu machen.
Speziell zur Einbindung von C‑Bibliotheken
eine Bemerkung (hier Zeilen 24+25):
Statt der C‑Libs <time.h> und
<math.h> sollten die C++‑Pendants
<ctime> und <cmath>
verwendet werden.
Hintergrund ist, dass für
jede C‑Standard‑Bibliothek xxx.h
es eine entsprechende C++‑Bibliothek
cxxx gibt, die lediglich den Namespace
auf std setzt und ansonsten
die alte Fassung verwendet –
d.h. verwendet man xxx.h,
so wäre alles global verfügbar,
was vermieden werden soll (vgl. C++ Standard Library headers).
Der Präprozessor kann auch bestimmte Konstanten
definieren (Textersetzung;
in Phase 2 wurde dies bewusst
durch konstante Strings ersetzt, in Phase 1
waren es Zeilen 32‑36 für ASCII-Steuercodes
zur Farbwahl).
- Struktur:
Je nach Projekt
kann der Programmierstil
deutlich variieren.
Man sollte sich einen aussuchen und
bei eigenen Projekten durchhalten,
so dass man intuitiv Fehler finden kann.
Bei existierendem Code sollte man sich
anpassen –
oder alles umschreiben.
Bei einem Team sollte man sich möglichst
auf den Code-Stil einigen
(siehe auch C++‑Code‑Standards von Standard C++ Foundation, Google, GitHub, geosoft, KDE-Framework|-Libs|Qt, Bjarne Stroustrup's C++ Style and
Technique FAQ;
und C-Code-Standards von GNU und Linux).
Hier habe ich (fast) alles auf Deutsch
kommentiert, natürlich ist
bei internationalen Projekten Englisch angesagt.
a) Zusammengehörigkeit:
Man sieht, dass {...} bestimmte Blöcke
zusammen gehören (z.B. Zeilen 62+73, 64+67,
oder 68+72),
ebenso dass ...;
eine Anweisung mit Ende
bezeichnet (z.B. Zeilen 66, 159
oder 173; diese Anweisungen werden immer nacheinander
abgearbeitet – bei Ausdrücken erlebt man
Überraschungen: hier kann der Compiler
optimieren) oder dass (...)
Ausdrücke beinhalten, die z.B. wahr
oder falsch sein können (Typ bool mit Literalen true {=1; ggf. auch
eine größere Zahl} und false
{=0},
z.B. Zeilen 63, 168 dreifach, 381 dreifach
oder 680 dreifach).
Nach if muss
kein Leerzeichen / Blank folgen,
{ kann direkt
nach der Verzweigungs- oder Schleifenanweisung kommen.
Dass hier zugehörige
geschweifte Klammern die selbe Einrückung haben
(also untereinander stehen)
oder niedere Blöcke
genau zwei Leerzeichen mehr eingerückt sind,
ist meine Präferenz, auch dass ich nie
Tabulatoren gebrauche (die leider
im Makefile Pflicht sind).
Gebrächlich sind 2 oder 4
(ganz selten, z.B. dem Linux-Kernel,
auch 8) Blanks oder ein Tab
als Einrücktiefe.
b) Kommentar-Arten:
Vermeidung von Kommentaren der Art /* ... */
hat den Vorteil,
dass man dann mit diesem Stil
große Bereiche auskommentieren kann (vgl. Kommentarabschnitt oben).
c) Namenskonventionen:
Bei Variablen klein beginnen und dann CamelCase:
anzahlErfolgterAufrufe
(bzw. bei Klassenvariablen
mit Underscore _
abschließen: anzahlErfolgterAufrufe_),
bei Funktionen wie Variable
oder auch snake_case:
wer_findet_funktion()
[mit Phase 2 habe ich mich entschlossen,
wer_findet_funktion ()
zu verwenden,
also Funktionbezeichner und Argumenklammern
mit einem Leerzeichen abzutrennen –
dies ist allerdings sehr unüblich,
mich hat es anders gestört],
einfache Typen klein mit Unterstrich und Endung:
adress_typ,
Klassen groß beginnen mit CamelCase,
Konstanten, Enum-Elemente und Makros groß mit Unterstrich:
SMILEY_FROWNING.
- Algorithmus:
Als Mathe-Lehrer, der den Schülern
ab der Klassenstufe 6 beibringt,
eine Bruchaufgabe sei nur
bei vollständig gekürztem Bruch
auch vollständig gelöst und
somit die volle Punktzahl wert,
ist ein Programm zur Ausgabe der Primfaktoren
(PFs) natürlich naheliegend. 😉
Was passiert aber mathematisch
in der Funktion primeFactors:
Schritt 1 (Zeilen 219‑225):
Die eigentlich zu zerlegende Zahl n
(hier als Aufruf-Parameter übergeben,
Zeile 462, oder im laufenden Programm eingegeben,
Zeile 514)
wird zuerst durch 2 geteilt (halbiert),
bis dies nicht mehr restfrei
geht (d.h. die verbleibende Zahl
ist ungerade und ist das neue n,
wenn das ursprüngliche n
gerade war).
Die Variable n ist immer der Quotient,
in dem noch nicht getestete Faktoren
stecken können. Bei jedem gefundenen PF
gibt es einen neuen Wert für n,
der sich durch Teilen mit dem gefundenen PF
ergibt (dies gilt auch für den folgenden
Schritt 2).
Schritt 2 (Zeilen 226‑237):
Nun wird nacheinander die zuvor erhaltene
ungeraden Zahl n
durch Zahlen i von 3
bis zu sqrt(n)
[d.h. square root (n) =
Wurzel (n) = √n]
jeweils so oft
wie restfrei möglich geteilt
(analog Schritt 1),
wobei nur ungerade i getestet werden.
Hierzu sind ein paar Bemerkungen
zum besseren Verständnis nötig:
- Da bereits der Primfaktor 2
in Schritt 1 bearbeitet wurde, muss hier
mit i = 3 begonnen werden.
- Es müssen nur ungerade Zahlen
getestet werden (dies wird in Zeile 229
durch i=i+2 erreicht),
denn außer 2 sind alle anderen geraden Zahlen
nicht prim. Zudem wurde durch Schritt 1
eine ungerade Zahl n erzwungen, so dass
die geraden Zahlen keine Divisoren i
für Teilen ohne Rest darstellen.
- Da der Laufindex inkrementiert wird,
d.h. sich von klein zu groß wandelt,
werden Nicht-Primzahlen keine Teiler i
sein können, da diese Faktoren besitzen,
um die n bereits beraubt wurde.
- Hier darf n als am Ende
von Schritt 1 eingefroren betrachtet werden:
Wurzel n wäre die größte Zahl,
die zweimal als Faktor in n stecken kann.
Eine Zahl größer Wurzel (n)
kann damit nur einmal in n stecken.
Diese als einzige von Schritt 2
nicht behandelte Möglichkeit
behandelt Schritt 3.
Wenn sich durch diese for-Schleife
am Ende n = 1 ergibt
(n = 2 ist nicht möglich
wegen Schitt 1, daher ist (n > 2)
in Zeile 241 in Ordnung),
dann ist die Primfaktorzerlegung bereits geschafft.
Ansonsten kommt nun
Schritt 3 (Zeilen 238‑244):
Wie in Punkten 3. und 4.
von Schritt 2 ausgeführt,
kann n, wenn es nicht 1 ist,
nur eine Primzahl sein, die größer als
√n ist.
Es gilt also nur noch, diese Primzahl n
der Liste hinzuzufügen.
Fertig! 😎
Man ersieht hier, dass man
mit brute force,
d.h. durch gewaltsames Teilen,
sinnvoll und schnell zum Ziel kommt,
lediglich die beschriebenen Stellen sind logisch
zu bedenken. Der Computer berechnet viele Operationen
schnell und fehlerfrei, Menschen gehen daher
anders vor – dies ist beim Programmieren
im Auge zu behalten.
Speziell auch, wann sich eine Optimierung
durch einen geschickteren Algorithmus lohnt und
wann es direkt geht.
- Mini-Benchmark:
Um den letzten Gedanken am Ende
des Algorithmusabschnitts weiterzuführen,
kann ein Benchmark Klarheit über Schwächen
geben und sinnvolle Änderungen
am Code auslösen – oder auch
die entsprechende verwendete Hardware testen.
Speziell nach Erweiterung von 31 Bit
für natürliche Zahlen (ℕ)
mit int
auf 64 Bit unsigned long long,
liegt ein solcher Test nahe,
da bei der größtmöglichen Primzahl
18 446 744 073 709 551 557
(über 18 Trillionen!)
sehr viele Berechnungen erfolgen und somit
die Zeitangabe auch sinnvoll zu erfassen ist.
Bei Aufruf
von time ./example 18446744073709551557 1 bzw. time make r 18446744073709551557 1
ergaben sich folgende Werte
auf den angegebenen Systemen:
System:
[🔧PC‑Tech‑Info] |
Intel Core 2 Duo
T6400@ 2,0 GHz
❹ Penryn
bogomips: 3989,82 |
Pentium Dual-Core
T4300@ 2,1 GHz
Penryn
bogomips: 4189,40 |
Intel Core
i7-2600K@ 3,4 GHz
❸ Sandy Bridge
bogomips: 6799,86 |
Intel Core
i7-4770T@ 2,5 GHz
❷ Haswell
bogomips: 4988,40 |
Intel Core
i7-6700@ 3,4 GHz
Skylake
bogomips: 6816,00 |
AMD Ryzen
5 3600@ 3,6-4,2 GHz
❶ Zen2 & RDNA 1.0
bogomips: 7186,43 |
|---|
| real: |
35,339 s |
33,724 s |
25,132 s |
23,829 s |
17,259 s |
16,046 s |
|---|
| user: |
35,288 s |
33,620 s |
25,107 s |
23,825 s |
17,255 s |
16,024 s |
|---|
| sys: |
0,004 s |
0,008 s |
0,009 s |
0,005 s |
0,004 s |
0,000 s |
|---|
Die System‑Angaben entstammen dem Befehl:
cat /proc/cpuinfo
bis auf den Codenamen
(der bei meinen Systemen
fettgedruckt erscheint; Backup‑ oder deutlich
veraltete Systeme erscheinen kursiv).
Für die größtmögliche ULL‑Zahl
18 446 744 073 709 551 615 (58 mehr als die Primzahl zuvor)
braucht mein Haswell‑System
statt 23,829 s
lediglich 0,015 s und
zerlegt dabei in sieben Primfaktoren:
3, 5, 17, 257, 641, 65537 und 6700417.
Der Code ist für Einzelzahlen
also schnell genug und der Mini-Benchmark
ein nettes Abfallprodukt.
- Lizenz und Urheberrecht:
Wenn man privat Code schreibt, besitzt man
das Copyright und sollte dies
auch anmerken. Dies gibt das Recht,
den Code zu verkaufen, aber natürlich ebenso,
diesen im Form von Freier Software der Allgemeinheit
zu überlassen
(Copyleft), so dass niemand
diesen Code missbrauchen kann,
sondern nur abändern und ebenfalls
im Quellcode der Allgemeinheit zur Verfügung
stellen muss.
Dies macht die GNU General Public License: GPL,
deren jüngste und mächtigste Variante
zur Befreiung der Anwender die GPLv3 ist.
Der von mir nur gelinkte Text
wird normalerweise dem Software-Quelltext
als Datei beigelegt.
Hier bedeutet mein Copyright nur,
dass ich es geschrieben habe und die Nutzung freigebe –
die Basis-Struktur kam aus einem Beispiel meiner 1. Literaturangabe
(S. 63, Listing 4.2),
der Algorithmus ist wohl bekannt und im Netz
vielfach leicht zu finden, ebenso die ANSI-Farbsequenzen, die ich schon
Ende der 1980-er in Tubo Pascal verwendete.
In Phase 2 kamen dann weitere Ideen aus der 1. Literaturangabe (Listing 10.6
[Exception: try/catch-Blöcke;
oben Zeilen 637-763-769], S. 233;
Listing 12.6 [variable Ausgabe
via ostream], S. 261) hinzu,
ebenso eine Literaturrecherche bzgl. ULL, Standardstring-Umgang
und weiteren Themen, wobei auch viel Code
verworfen bzw. umgeändert werden musste.
Somit ist vorrangig die spezielle Gesamtgestaltung
mein Werk.
Nichts hier ist also ein Copyright
(Urheberschaft macht bei sehr Einfachem
wenig Sinn; wenn das mal die Patentämter
[bzw. die verantwortliche Legislative]
begreifen würden) oder
eine Lizenz wert ... es soll nur
als Beispiel dienen,
wie man mit eigener Software umgehen sollte.
- Feinheiten:
So, wie die Farbcodes im Teminal über ANSI-Escape-Sequenzen eine neue Farbe festlegen (Kommentar und Festlegung
in Zeilen 27‑53,
Anwendung z.B. in Zeilen 69+154+711+715),
so gibt es auch in String-Angaben bzw. allgemein
in C/C++ Escape-Sequenzen,
z.B. um einen Zeilenumbruch: \n (new line;
vgl. Zeile 120+255+292+699),
ein Unicode-Zeichen über \Uhhhhhhhh
zu bewirken (vgl. z.B. Zeile 77 dreimal+82+137+502+511)
auch das doppelte Anführungszeichen: "
zu maskieren, das ja als Beginn- bzw. Endemarke
eines Strings dient und somit im String
als \"
dargestellt werden muss.
Die Escape-Sequenzen beginnen immer
mit einem Rückwärtsschrägstrich /
Backslash: \\.
Im Übrigen werden Escape-Sequenzen
auch in Druckersprachen
wie ESC/P (Epson) oder
PCL (HP) verwendet,
wenn keine Seitenbeschreibungssprachen wie PostScript
verwendet wird.
Eine Vereinfachung ist
in Zeilen 60 (schmal)+177 (breit)
zu finden, so dass der Namespace
für die angegebene Funktionen oder gar
alle Funktionen im Block
nicht mit std::
ausgewiesen werden muss.
Man kann also auch in einer Zeile
für alle Funktionen
der Standardbibliothek schreiben:
using namespace std; // fuer std::cout und std::endl - aber auch bei anderen wirksam
Diese allgemeine Änderung sollte aber eher
vermieden werden, insbesondere wenn in main
oder gar global umdefiniert,
weil hier Mehrdeutigkeiten
eingeführt werden könnten.
Daher lieber nur für häufig
aufgerufene Bibliotheks-Funktionen in einer Funktion
oder in einer überschaubaren Funktion,
in der kaum eigene Bezeichner vorkommen,
umdefinieren wie im Listing gezeigt.
- Kommt noch was?:
Nicht alles
ist erklärt ... und wird es
wohl auch nie (auch wenn ich
auf Hinweise eingehe).
Dafür sei die Literaturliste
und eine Internetrecherche empfohlen.
Nach der deutlichen Umarbeitung zur Phase 2
ist noch offen, was als Nächstes ansteht.
Die Phase 1 (08.08.2019) dieses Programms
habe ich auf einer Website
eingefroren – inkl. der ehemaligen Phase 1-Download-Datei.
Ideen hätte ich genug ...
auch für ganz andere Programme ...
oder einen Programmierkurs für Heranwachsende,
der sich an einen 📢Vortrag
anschließen könnte (diese Idee
hat bereits vieles
von Phase 2 geleitet).
Ergänzungen
Wie man nun auf der Kommandozeile mit dem Programm
umgeht, d.h. die einzelnen Programmierschritte auslöst:
den Quelltext editiert, diesen übersetzt und
das ausführbare Programm aufruft,
kann man oben beim Makefile nachlesen.
Hier die Ausgabe im xfce4-terminal
(mit Startparameter 14.323232-696/435l0xAB,
d.h. fünf Zahlen (mit Trennern . + - + / + l),
sowie der Eingabe
von erst 18446744073709551615 und
dann von 25,99,1,
d.h. zwei Zahlen und dem Abbruch-Code):
die Ausgabe im inversen Modus
(mit den drei Startparametern
-i, 666,-999,0xAFFE, sowie
zum Abbrechen 1):
sowie die des Versions- und Hilfstextes
durch make r -b:
Das Beispielprogramm steht mit dem Makefile
zum direkten Download
weiter unten bereit.
Zum Binary, d.h. der Datei
des ausführbaren Programms in Maschinencode,
noch ein paar Infos
bzw. wie man sich diese beschafft:
$ ls -al example_debug example
-rwxrwxr-x 1 jmb jmb 60464 Sep 7 15:14 example_debug
-rwxrwxr-x 1 jmb jmb 56616 Sep 7 15:14 example
# d.h. 60464 = 59,05 kB / 56616 = 55.29 kB Größe
$ file example
example: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=f59476f8f7efd2f9dc548143f262f53b1191c37e, for GNU/Linux 3.2.0, not stripped
$ strings example
# Ausgabe aller Zeichenketten (Strings) des Executables (viel: 649 Zeilen)
$ readelf -x .rodata example
# Anzeigen der statischen Strings
$ nm example
# Auflisten der Symbole
$ readelf -s example
# Anzeigen der Symbole
$ readelf -h example
# Ausgabe des ELF (Binärformat unter Linux) - Headers
$ readelf --relocs example
# Klären, ob das Binary ein positionsunabhängiges Executable ist bzgl. der Bibliotheken.
$ ldd example
# Liste dynamisch gelinkter Bibliotheken (hier sechs: linux-vdso.so.1, libstdc++.so.6, libm.so.6, libgcc_s.so.1, libc.so.6, /lib64/ld-linux-x86-64.so.2)
$ ldconfig -p | grep NAME_BIBLIOTHEK
# Nachschauen, ob eine bestimmte Bibliothek auf dem System installiert ist, z.B. bei `ldconfig -p | grep libm.so.6' u.a. `... => /lib/x86_64-linux-gnu/libc.so.6'.
$ /lib/x86_64-linux-gnu/libc.so.6
# liefert am Anfang: 'GNU C Library (Ubuntu GLIBC 2.29-0ubuntu2) stable release version 2.29.' auf Xubuntu 19.04.
$ objdump -d example
# Disassemblieren des Binary bzw. des Object Files (*.o)
$ strace ./example
# Lässt das Programm ablaufen und berichtet, was es dabei tut.
Dies sind ein paar Beispiele,
wobei zumeist auf die GNU Binary Utilities
(kurz binutils, ebenso Name des Pakets,
in dem neben Assembler as und Linker ld
und gold
diese Werkzeuge für ausführbare Dateien
enthalten sind; diese werden, wie bereits ausgeführt,
typischerweise gemeinsam mit gcc,
make und
gdb verwendet;
vgl. Homepage sowie Dokumentation
zu GNU Binutils; siehe auch Phoronix‑Artikel zum Release
von 2.45 vom 27.07.2025;
bzw. zum Phoronix‑Artikel zum Release
von 2.44 vom 02.02.2025;
bzw. zum Phoronix‑Artikel zum Release von 2.43
vom 04.08.2024,
bzw. zum Phoronix‑Artikel zum Release von 2.42
bzw. original Ankündigung,
beide vom 29.01.2024, Phoronix‑Artikel zum Release von 2.41
vom 30.07.2023, Phoronix‑Artikel zum Release von 2.39
bzw. original Ankündigung,
beide vom 05.08.2022, LWN‑Bericht zum Release von 2.38
vom 09.02.2022, Phoronix‑Artikel zum Release von 2.37
vom 18.07.2021, vom Release von 2.36
vom 24.01.2021,
zum Start der Stabilisierungsphase
von Binutils 2.35 vom 05.07.2020, dem Phoronix‑Artikel zu Version 2.34 vom 01.02.2020 bzw. zur Version 2.33.1 vom 12.10.2019)
zurückgegriffen wurde.
Es wäre wünschenswert, wenn man einem Binary
auch die Compilerversion und die benutzten Flags
entlocken könnte, wie es ein aktuelles
GCC‑Proposal gerade vorschlägt (vgl. GCC Developers Discuss New Option
For Recording Compiler Flags / Details In Binaries, Phoronix, 16.11.2019).
Die allgemeinen Unix‑Befehle
werden unter GNU/Linux von GNU Core Utilities bereitgestellt
(kurz coreutils, ebenso Name des Pakets,
das die gut bekannten Befehle enthält, wie z.B.:
ls, pwd, who, cat, echo,
head, sort, wc,
cut, tr, chmod, touch,
mv, rm, mkdir, rmdir,
sync, df, du, dd),
die aktuell in Version 9.5 vorliegen (siehe Official‑Announcement, 28.03.2024;
vgl. vorige Versionen 9.4 Phoronix‑Artikel, 29.08.2023;
9.2, Phoronix‑Artikel, 20.03.2023;
9.1, Announcement, 15.04.2021 bzw. Phoronix‑Artikel, 16.04.2021;
zur Version 9.0 siehe Announcement, 24.09.2021).
Auch diese Befehle sind zum Teil
für Binaries relevant.
[Uutils ist ein in Entwicklung
befindlicher Ersatz für GNU Coreutils, der aber
statt in C in Rust geschrieben wird
und aktuell in Version
Uutils 0.8.0 vom 06.04.2026
vorliegt (siehe Phoronix‑Artikel, 06.04.2026 –
vgl. 0.7.0, Phoronix‑Artikel, 09.03.2026
[Canonical verwendet es
in Ubuntu 25.10 STS, was allerdings
viele Probleme aufzeigte – die leider
noch nicht behoben wurden] –
vgl. 0.6.0, Phoronix‑Artikel, 02.02.2026 –
vgl. 0.5.0, Phoronix‑Artikel, 14.12.2025 –
vgl. 0.4.0, Phoronix‑Artikel, 09.11.2025 –
vgl. 0.3.0, Phoronix‑Artikel, 24.10.2025 –
vgl. 0.2.0, Phoronix‑Artikel, 06.09.2025 –
vgl. 0.1.0, Phoronix‑Artikel, 24.05.2025 –
vgl. 0.0.30, Phoronix‑Artikel, 08.03.2025 –
vgl. 0.0.29, Phoronix‑Artikel, 19.01.2025 –
vgl. 0.0.28, Phoronix‑Artikel, 17.11.2024 –
vgl. 0.0.27, Phoronix‑Artikel, 23.06.2024 –
vgl. 0.0.26, Phoronix‑Artikel, 27.04.2024 –
vgl. 0.0.25, Phoronix‑Artikel, 23.03.2024 –
vgl. 0.0.24, Phoronix‑Artikel, 26.01.2024 –
vgl. 0.0.23, Phoronix‑Artikel, 16.11.2023 –
vgl. 0.0.22, Phoronix‑Artikel, 16.10.2023; vgl. 0.0.21,
Phoronix‑Artikel, 04.09.2023; vgl. 0.0.20,
Phoronix‑Artikel, 14.07.2023; vgl. Phoronix‑Artikel, 08.02.2023:
Präsentation zur FOSDEM 2023
vom Hauptentwickler Sylvestre Ledru;
vgl. Version 0.0.19, Phoronix‑Artikel, 05.06.2023;
vgl. Version 0.0.18, Phoronix‑Artikel, 03.04.2023;
vgl. Version 0.0.16, Phoronix‑Artikel, 12.10.2022; bzw. zu Uutils 0.0.13 vom 03.04.2022 –
siehe auch Release‑Liste).]
Bislang habe ich nichts
zum Reverse‑Engineering oder zur Manipulation von Binaries
gesagt – es ist ja immer besser, den Quellcode
zu haben und nach Änderungen neu zu kompilieren
(was unter 🐧GNU/Linux
die Distributionen dankenswerter Weise übernehmen).
Aber manchmal, nicht nur aber eben auch
bei vielen 🕹️Spielen,
ist es sinnvoll,
auch ohne Quellcode eingreifen zu können ...
und somit hier als Heads‑Up
die Erwähnung eines schnell reifenden GNU‑Tools:
GNU poke
(die Projektseite: poke 1.0
vom 26. Feb. 2021; siehe auch Vortrag von 2019
zu Kernel Recipes; dann kam Version poke 1.3 mit Erweiterungen:
u.a. ist nun das libpoke Headerfile
kompatibel mit C++; die Version GNU Poke 2.0 vom 27.01.2022
als LWN‑Announcement, die Version GNU Poke 2.3 vom 31.03.2022,
die Version GNU Poke 3.0 vom 26.01.2023,
die Version GNU Poke 3.2
vom 13.05.2023,
die Version GNU Poke 3.3
vom 20.08.2023
und die aktuelle Version (siehe GNU Poke
FTP Server)
GNU Poke 4.0 vom 30.03.2024
[nun gibt es neben poke‑4.0.tar.gz
auch noch poke‑elf‑1.0.tar.gz],
zudem gibt es zur neuen Version auch ein Manual).
Wer das Makefile,
den Quelltext
des obigen C++‑Beispielprogramms und die Executables
für Linux haben möchte,
kann es einfach als gezippte Tar‑Datei
jmb_added_for_cpp_programming.tgz (52,2 kB,
Fassung vom 07.09.2019 – d.h. komplette
Phase 2)
downloaden und an passender Stelle
zum neuen Unterverzeichnis jmb mit den vier Dateien
(Makefile, example_debug, example und example.cpp)
entpacken über: tar xvfz jmb_added_for_cpp_programming.tgz.
[Siehe auch Link zum Download
der ehemaligen Phase 1 vom 08.08.2019.]
Link zu den
🐧empfohlenen Programmen.
Weiterführende Literatur &
Online Quellen
- C++‑Programmierung allgemein: ...
- ... Buch‑Form:
- C++ –
Das umfassende Handbuch
(aktuell zu C++17) [Errata &
Listings], Torsten T. Will,
Rheinwerk Computing,
2019 (1. korrigierter Nachdruck
der 1. Aufl. 2018), 1067 S.
[erstes Viertel gelesen ...
Anfang meines Programmierens
mit hier vorgestelltem
Faktorisierungs‑Programm]
![[Amazon-Icon]](images/amazon_inside.gif) C++ – kurz & gut
(aktuell zu C++17),
2018 (3. Aufl.), 228 S.
[Vorsicht: keine Einführung,
dafür aktuelle Übersicht {C++20 wird
mit den nächsten Standards erst
wirklich benutzbar}]
C++ – kurz & gut
(aktuell zu C++17),
2018 (3. Aufl.), 228 S.
[Vorsicht: keine Einführung,
dafür aktuelle Übersicht {C++20 wird
mit den nächsten Standards erst
wirklich benutzbar}]- C++17 Standard Library Quick Reference:
A Pocket Guide to Data Structures, Algorithms,
and Functions (Englisch),
Peter Van Weert & Marc Gregoire,
Apress, 07/2019 (2nd Ed.),
320 S. [kurz überflogen; Order & Download]
- Professional C++
(Englisch), Marc Gregoire,
22. März 2021 (5. Ed.),
Wrox, 1312 S. (Taschenbuch),
Wrox, ISBN 978‑1119695400
[beim Überfliegen; Seiten recht dünn:
man erkennt den Druck der Rückseite;
US‑Order & Download]
- Die C++ Programmiersprache
(Deutsche Ausgabe der Special Edition),
Bjarne Stroustrup, Addison-Wesley Verlag,
2000 (4. aktualisierte Auflage),
1068 S. [in 2000 oder direkt danach
gekaufte Originalausgabe;
damals bis zur Hälfte gelesen]
- A Tour of C++ (C++ In Depth
SERIES), Bjarne Stroustrup, 2018,
239 S., Addison Wesley, 2nd Edition,
ISBN 978-0134997834 [beim Einlesen]
- Clean Code: A Handbook of
Agile Software Craftsmanship,
Robert C. Martin, 2008, 464 S., Prentice Hall,
ISBN 978-0132350884
[noch nicht gelesen]
- ...
Online‑Quellen:
- Programmierwerkzeuge allgemein: ...
- ... Buch‑Form:
- ...
Online‑Quellen:
- Spiele‑Programmierung
mit C++: ...
- ... Buch‑Form:
- Beginning C++ Through Game Programming,
Michael Dawson, 06/2014, 390 S.,
Cengage Learning, 4th Edition,
ISBN 978-1-305-10991-9
[beim Einlesen; sehr einfache Basics]
- C++ Game Programming –
Second Edition,
John Horton >Homepage<, 10/2019,
746 S., Packt Publishing,
ISBN 978-1-83864-857-2, >Download
der Farbbilder< & >Sourcecode: grün Code,
Download ZIP<
[lese quer ... SFML‑Einsatz direkt
von Beginn ab –
interessanter Einstieg]
- SFML Blueprints
(English Edition),
Maxime Barbier, 05/2015, 298 S., Packt Publishing,
ISBN 978-1-78439-847-7 [bestellt]
- SFML Game Development
(English Edition),
Jan Haller, Henrik Vogelius Hansson, Artur Moreira,
06/2013, 296 S., Packt Publishing,
ISBN 978-1-84969-684-5, >Sourcecode: grün Code,
Download ZIP<
[noch nicht gelesen]
- SFML Game Development By Example
(English Edition), Raimondas Pupius,
12/2015, 522 S., Packt Publishing, ISBN 978-1-78528-734-3
[noch nicht gelesen]
- Abgekündigt:
SFML Essentials
(English Edition),
Milcho G. Milchev, 02/2015, 156 S., Packt Publishing, ISBN 978-1-78439-732-6
[nicht im Besitz –
abgelöst durch die beiden Werke
direkt darüber
von Haller et al. bzw. Pupius]
- C++ Game Development
By Example, Siddharth Shekar, 05/2019,
408 S., Packt Publishing, ISBN 978-1-78953-530-3
[noch nicht gelesen]
- ... Online‑Quellen:
- Siehe Liste
der weiterführenden Literatur:
- 📋PDF-Downloads und
📢Vortrags-Zusammenfassungen.
Link zum 🐧persönlichen Hintergrund bzgl. GNU/Linux.
Eigene Erfahrungen und Motivation
Vor 1987 und dem ersten PC habe ich in den Ferien ein ausgeliehenes
Schulbuch und die Anleitung zu Turbo Pascal gelesen.
Mit dem Computer begann ich auch sofort,
mein erstes Programm zu schreiben:
ein Menüprogramm unter DOS, das sowohl Programme
von Festplatte laden konnte als auch
von 3.5" Diskette sowie die Uhrzeit
über TSR-Routinen
(Terminate and Stay Resident)
sekundengenau anzeigte.
Unter DOS nicht ganz einfach.
Als nächstes suchte ich geeignete BASIC-🕹️Spiele-Listings,
tippte sie ab und brachte sie zum Laufen,
um sie dann in Turbo Pascal erneut zu programmieren.
Wegen Unzufriedenheit mit der Steuerung suchte ich
den Tastaturpuffer,
der bei IBM PS/2 nicht dokumentiert und nicht unter
der Speicher-Adresse voriger PCs zu finden war ...
inkl. ersten Reverse-Engineering-Methoden,
bis dies erfolgreich mit Assembler-Routinen ansprechbar war.
Dennoch habe ich das Pacman-Spiel, um das es ging,
nie mit der angedachten hohen Auflösung
(für damalige Zeiten, d.h. mehr als
den MCGA-Standard: 320 × 200 pix)
weiterentwickelt.
Daneben programmierte ich direkt
den Laserdrucker, der eine deutlich
höhere Auflösung mit 300 dpi
(entspricht bei DIN A4
3508×2480 pel =
8,7 Mpel,
entsprechend 4k = UHDTV1 =
3840×2160 pix =
8,3 Mpix)
als der Bildschirm hatte
(vgl. Bildschirm:
Auflösung und Fläche der Seite
👑König Desktop).
An der Uni lernte ich für PraMa
(heute würde man
eher Numerik sagen)
die Programmiersprache C, nachdem die Tutoren
Turbo Pascal
nicht verstanden –
als es genauso zäh mit C lief,
brach ich ab (ich bekam immer sehr gute Noten,
die Erklärungen zogen sich aber meist
eine Stunde hin, bis diese Tutoren
den jeweiligen Algorithmus
verstanden ...).
In der Forschung lernte ich dann auch Fortran kennen
(und verwendete es neben C),
allerding passte ich zumeist nur den Code zum Kompilieren
auf DEC OSF-Alpha bzw. Debian 🐧GNU/Linux an,
patchte SW
zur astronomischen Bildverarbeitung
und änderte vorhandene Programme ab.
Als ich in die IT-Branche eintrat,
hatte ich nie einen Kurs, Vortrag, Vorlesung etc.
über Computer oder Programmieren besucht:
ich war reiner Autodidakt.
Dies hat sich nicht negativ bemerkbar gemacht,
eher positiv (ich hatte nie eine Sehnenscheiden-Entzündung,
da ich das 10-Finger-System
nicht erlernte).
Allerdings war ich im professionellen Umfeld vorrangig
mit Scripten beschäftigt, zumal ich überwiegend
für proprietäre Unixe zuständig war.
Und privat habe ich in dieser Zeit den Computer
eher gemieden.
Ich habe mich nie als Programmierer gesehen –
und suche nun ein paar Herausforderungen,
um ggf. Heranwachsende für hochwertiges Programmieren
zu interessieren –
kein Java und Rumschubsen der Maus,
worauf ich schon angesprochen wurde.
Erste Anfänge dieser Idee sind hier
bereits sichtbar ...
Ob ich tatsächlich wieder anfange, kleine 🕹️Spiele
zu programmieren (siehe auch 🕹️Persönlicher Hintergrund),
was mich jüngst zu C++ bewog,
wird sich zeigen.
Mein Interesse wird sich aber vorrangig auf C++ und C konzentrieren.
Link zu 🌠meiner generellen Motivation.
Bei Fragen / Problemen mit dieser Seite bzw.
meiner Webpräsenz kontaktieren Sie mich bitte:
E-Mail: 📧jmb@jmb-edu.de
©️ 1987‑2026 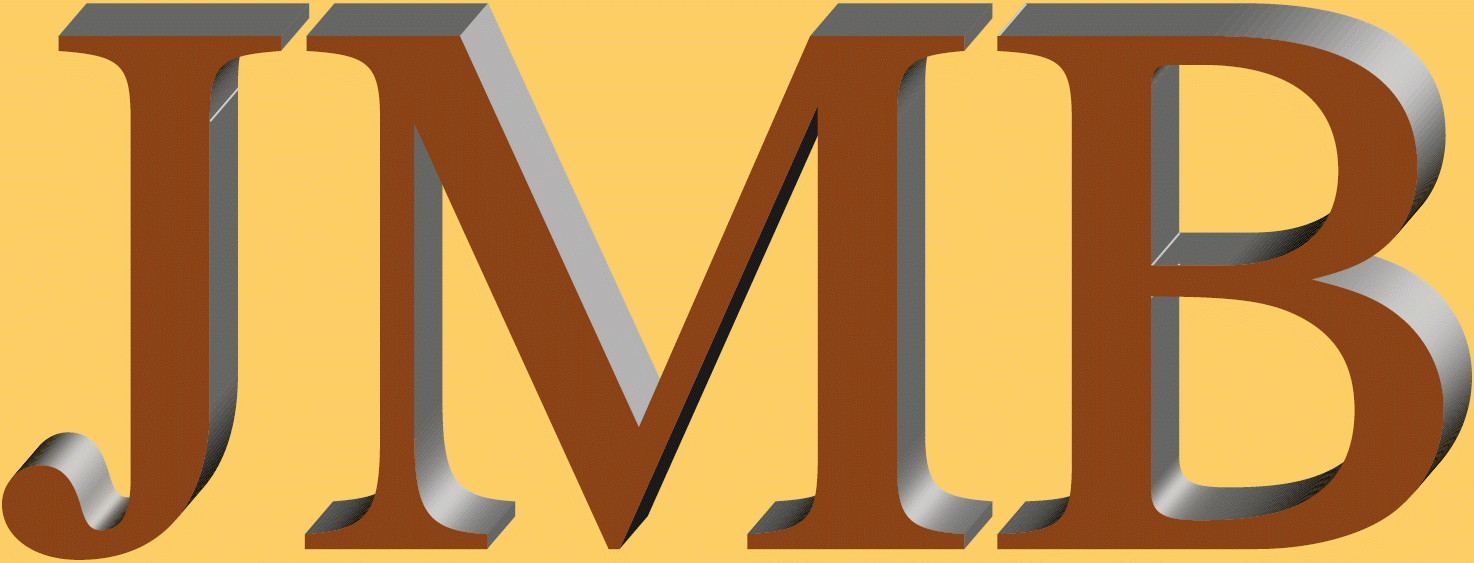 Bitte beachten Sie hierzu auch mein 📄Impressum.
Bitte beachten Sie hierzu auch mein 📄Impressum.

[Zurück zur 🏁Startseite]
| Erste Fassung: | 30. | Juli | 2019 |
| Letzte Änderung: | 01. | Juli | 2026 |

![[Output des Hilfstextes von Makefile]](images/Makefile_info_output_20190906.gif)
![[Output des C++-Beispiel-Programms]](images/example_output_cpp_start.gif)
![[Output des C++-Beispiel-Programms im Invers-Modus]](images/example_output_cpp_start_inverse.gif)
![[Output des C++-Beispiel-Programms bzgl. Versions- und Hilfsausgabe]](images/example_output_cpp_help.gif)